
Canonical tags are one of the most practical tools in technical SEO. They tell search engines which version of a page to index when multiple URLs serve similar or identical content.
Get them right, and you protect your crawl budget, consolidate link equity, and keep your rankings clean. Get them wrong, and Google might index the wrong pages or waste resources crawling duplicates you never intended to rank.
This guide covers what canonical tags are, how to implement them, and the best practices that keep your site's canonicalization working properly.
What are canonical tags in SEO?
A canonical tag is an HTML element (rel="canonical") placed in the head section of a web page. It tells search engines which URL represents the primary version of a piece of content.
When you set a canonical URL, you signal to Google that this is the page you want indexed and ranked, even if similar content exists at other URLs.
Canonical tags go in the head section of your page's HTML code. There are two types you can use depending on the situation:
- A canonical tag on a duplicate page pointing to the master version

- A self-referencing canonical tag on the master version
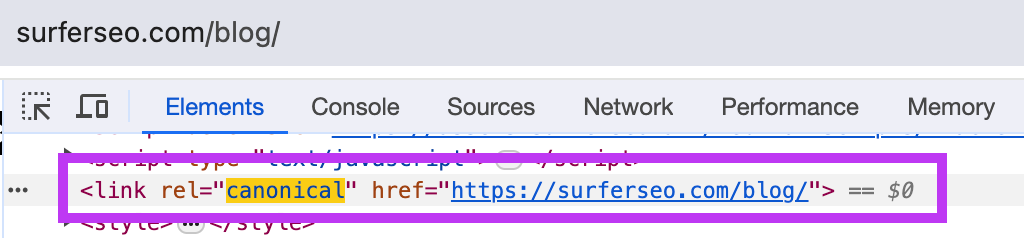
The first type redirects search engine attention from a duplicate to its primary counterpart. It signals to crawlers: "Skip this page and index the original instead."
A self-referencing canonical sits on the primary page itself, pointing to its own URL. It reinforces that page's authority and prevents URL variations from creating unintended competition.
Why canonical tags matter for SEO
Canonical tags address one of the most persistent challenges in SEO: duplicate content. When multiple URLs serve identical or near-identical pages, search crawlers struggle to determine which version deserves priority. This wastes your crawl budget and dilutes the ranking strength of every affected page.
Now you may be wondering, "Why would someone publish duplicate pages in the first place?"
The thing is, Google doesn't index actual pages, but their URLs. Each URL is seen as a unique page regardless of how similar the content is.
For example, let's say you're selling printables at www.exampleprintableswebsite.com. There may be many variants of your homepage, such as:
- https://exampleprintableswebsite.com
- http://exampleprintableswebsite.com
- https://www.exampleprintableswebsite.com
- https://exampleprintableswebsite.com/index.php
While each of these URLs would lead to the same page, they're all considered unique from the search engine's perspective. Without a canonical tag, they'd all be indexed and waste crawlers' time.
The same would happen with links to specific product filters and items, for example:
- https://exampleprintableswebsite.com/calendars.html
- https://exampleprintableswebsite.com/calendars.html?Year=2026
- https://exampleprintableswebsite.com/calendars.html?Year=2026&color=purple
These are all separate pages, even though the content is only slightly different. Such links are known as parameterized URLs, and they're one of the many causes of duplicate content.
By setting canonical tags for specific pages, you can manage your crawl budget more efficiently and consolidate link equity.
Doing so also contributes to the overall user experience, as the search results would lead to the most relevant and up-to-date version of your pages.
Canonicalization is also becoming relevant beyond traditional search. AI-powered systems like Google's AI Overviews, ChatGPT, and Perplexity ingest multiple versions of pages when generating answers. Clear canonical signals help these systems identify which URL to treat as authoritative, making proper canonicalization important for visibility in both organic results and AI-generated responses.
Does every page need a canonical URL?
Having a canonical URL on every page isn't mandatory, but it's considered an SEO best practice.
This helps to prevent issues with duplicate content and ensures that search engines prioritize the correct page in search results.
It's important to add only one canonical tag per page. Multiple canonical tags can cause confusion for search engine crawlers, potentially leading to incorrect indexing of content.
Does this mean Google would always see this version as the master one? Not necessarily, which takes us to the next section.
Can Google ignore canonical tags?
Yes. Google treats the rel="canonical" tag as a strong hint, not an absolute directive. If other signals point to a different URL, Google may override your declared canonical.
Google uses approximately 40 different signals to determine canonical URLs. These include:
- The rel="canonical" tag itself
- 301 and 302 redirects
- HTTPS vs. HTTP (HTTPS is preferred)
- Sitemap inclusion
- Internal linking patterns
- URL length and structure
Google also ranks canonicalization methods by strength. According to Google's documentation, the hierarchy is:
- Redirects (strongest signal)
- rel="canonical" link annotations (strong signal)
- Sitemap inclusion (weak signal)
When signals conflict, Google falls back on secondary factors to make its determination. A page that delivers the most value to users, with comprehensive and relevant content, is more likely to be treated as canonical.
Placing a canonical tag alone is not always enough. For Google to respect your preference, align all your signals: internal links, sitemaps, redirects, and canonical tags should all point to the same preferred URL.
How to implement canonical tags
There are several ways to specify the canonical version of a page, depending on the URL specifics and other circumstances. Let's dive into all the methods you can use.
Set canonicals using rel="canonical" HTML tags
The most common way to implement canonical tags is to place them in the head section of your page's HTML code.
Going back to the printables example, here's how the tag would look for your blog home page:

This method is suitable for those who know their way around HTML and are familiar with coding basics. If you're not among them, fret not—many content management systems (CMS) and plugins let you set canonical URLs without coding.
For example, the Yoast SEO plugin simplifies the canonicalization of your WordPress site by giving you a dedicated field for canonical URLs. You only need to paste the URL, and the tag will be set automatically.
Use canonicals in HTTP headers
Not every part of your website will be in HTML.
For example, you may publish freebies like whitepapers and downloadable guides, which will be in different formats (.doc, .pdf, etc.). In this case, you can place canonical tags in the HTTP header like so:

This option is useful if the same file comes in multiple formats and you want to specify the one you want users to find when searching for it.
Include canonicals in sitemaps
When you add a page to the sitemap, it's automatically suggested as canonical.
That's why you should only include the pages you consider canonical in your sitemap. Exclude every alternate page, and make sure to keep your sitemap updated with new canonical pages as you publish them.
Keep in mind that sitemap inclusion is the weakest canonical signal according to Google's documentation. It works best when combined with a rel="canonical" tag or redirect for stronger reinforcement.
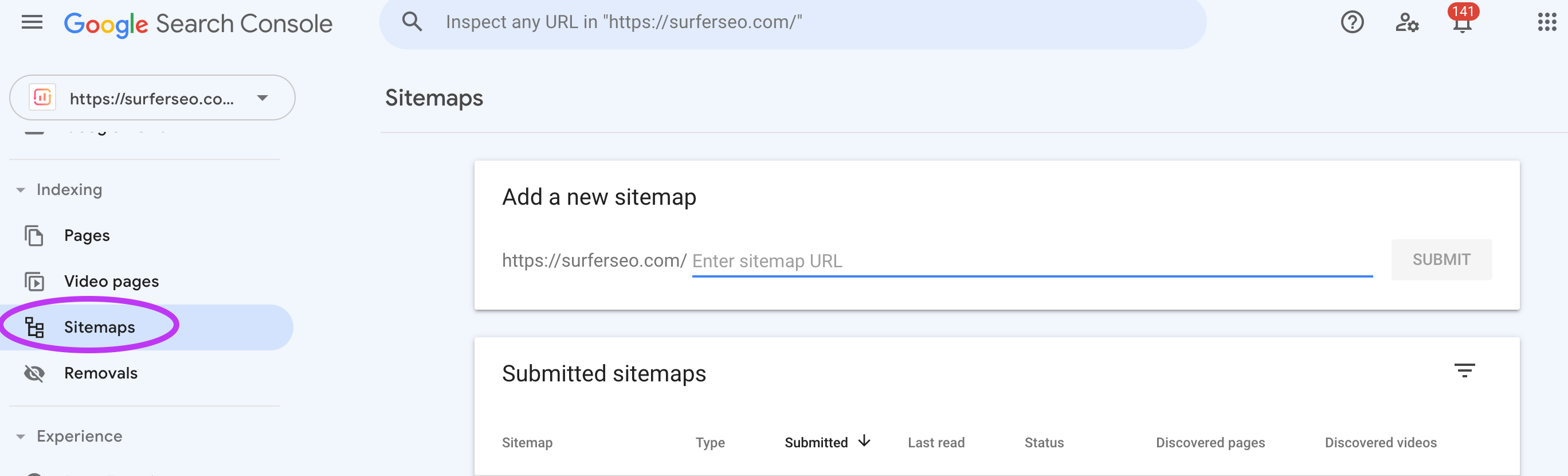
There are various generators you can use to create a sitemap without hassle, such as XML-Sitemaps. The majority of CMSs also allow you to autogenerate a sitemap.
You can then submit the sitemap through Google Search Console. Under Indexing > Sitemaps > Add a new sitemap.
Implement canonicals with 301 redirects
Redirects are the strongest canonical signal according to Google. A 301 redirect permanently sends both users and search engine crawlers to the canonical page automatically.
The specific steps for setting a 301 redirect depend on your CMS, though most make it easy enough to do it without much technical knowledge. You'll get a section dedicated to redirects, and all you need to do is define redirected URLs and the destination page.
Using redirects for canonicalization is especially useful if you're doing a more comprehensive URL restructuring to fine-tune your linking strategy. Since redirects carry the most weight in Google's canonical hierarchy, they're the best choice when a duplicate URL no longer needs to be accessible.
Handle canonicals on JavaScript-rendered pages
If your site is built with a JavaScript framework like React, Vue, or Angular, canonical tags need extra attention. Google processes JavaScript sites in two phases: first it crawls the raw HTML, then it renders the page with JavaScript. This creates a timing issue.
If the raw HTML contains one canonical URL and JavaScript changes it to another during rendering, Google receives conflicting signals. The result? Google may ignore your preferred canonical entirely.
In December 2025, Google updated its JavaScript SEO documentation with clear guidance on how to handle this:
- Preferred approach: Set the canonical URL in the raw HTML so it matches what the rendered JavaScript will display. This ensures consistent signals before and after rendering.
- Alternative: If JavaScript must set a different canonical URL, omit the canonical tag from the raw HTML entirely to avoid conflicts.
- Make sure only one canonical tag exists after rendering is complete.
You can use the URL Inspection tool in Google Search Console to compare how canonical tags appear in both the raw HTML and the rendered version of your page. This is the fastest way to spot mismatches.
7 canonical tag best practices
Now that you know the basics of implementing canonical tags, it's time to dive into the specifics and discuss some small but crucial steps you should take.
For best results, make sure to do the following:
1. Use absolute URLs
Absolute URLs contain all the data necessary to locate a page—the domain and the path. By contrast, relative URLs only contain the path, and they should be avoided when setting canonical tags because they might confuse search engine crawlers.
Suppose your printables website had a "how-to" section of the blog. The absolute URL with the canonical tag would look like this:

You technically can set a relative URL as a canonical, which would look like this:

Google advises against using relative URLs as this may lead to indexing issues.
2. Stick to lowercase letters in URLs
URLs are case-sensitive, so consistency is crucial when defining your canonical links.
Search engines might perceive uppercase and lowercase URLs as separate and consider them duplicate pages even though they're effectively the same page.
With this in mind, be extra careful when manually entering canonical URLs. Alternatively, you can implement server-side rules to enforce lowercase URLs across your website. Here's what the rule looks like:

This method involves a bit more extensive coding knowledge, so it might be best to consult a professional if you're not experienced in working with code.
3. Use the correct domain protocol
You know that "Not secure" message you get when visiting an HTTP page? Well, Google doesn't like to see it.
Using the secure HTTPS protocol is an important ranking factor, as users' online safety is one of Google's main priorities.
When setting canonical tags, don't forget to ensure consistency by including HTTPS instead of HTTP.
This is particularly important if you're currently not using the secure protocol and plan on migrating to it. As you do, update your canonical URLs to include the HTTPS versions of each page.
4. Specify trailing slash vs. non-trailing slash URLs
Speaking of consistency, another thing that shouldn't slip your mind when defining canonical URLs is a trailing slash—the "/" symbol at the end of a URL. For clarity's sake, here's an example of a URL with and without a trailing slash:
- Trailing slash URL: https://www.exampleprintableswebsite.com/
- Non-trailing slash URL: https://www.exampleprintableswebsite.com
These two links might look the same to you, but search engines treat them as separate URLs despite them having the exact same content.
5. Specify non-WWW vs WWW URLs
Similar to the above point, you need to decide whether your site will contain the WWW prefix or not, and then stick to your choice across your pages' canonical URLs.
As mentioned, any inconsistencies can be seen as duplicate content, even though the difference might seem minor.
Note that Google doesn't care much whether you'll use WWW or not, as this isn't particularly important for SEO. The only thing that matters is that you don't configure both URL versions simultaneously, especially without highlighting the canonical version.
6. Use self-referential canonical tags
As mentioned, self-referential, or self-referencing, canonicals are those that point to their own URL, as opposed to the canonicals that lead from the duplicate to the main version.
A self-referential canonical tag is particularly useful when multiple URL parameters lead to the same content, as they clarify which specific URL should be indexed.
Setting a self-referencing canonical involves the same process as implementing a regular one, except you'll include the given page's original URL.
So if you wanted to make https://exampleprintableswebsite.com/calendars.html canonical, you'd include this URL as it is in the corresponding tag.
7. Specify only one canonical tag per page
Having multiple canonical tags for one page is the same as not having any at all. It defeats the purpose of setting canonicals because it leads to indexing confusion and lets Google decide which page to rank.
In most cases, multiple canonicals are set accidentally. For example, you might set one in your CMS and do it again manually in the page's HTML.
To avoid this, make sure each page only has one canonical tag.
How to audit canonical tags for SEO
You can audit your website's canonical tags using a free tool like Google Search Console.
On GSC, go to Indexing > Pages. There, you will see the Why pages aren't indexed section.
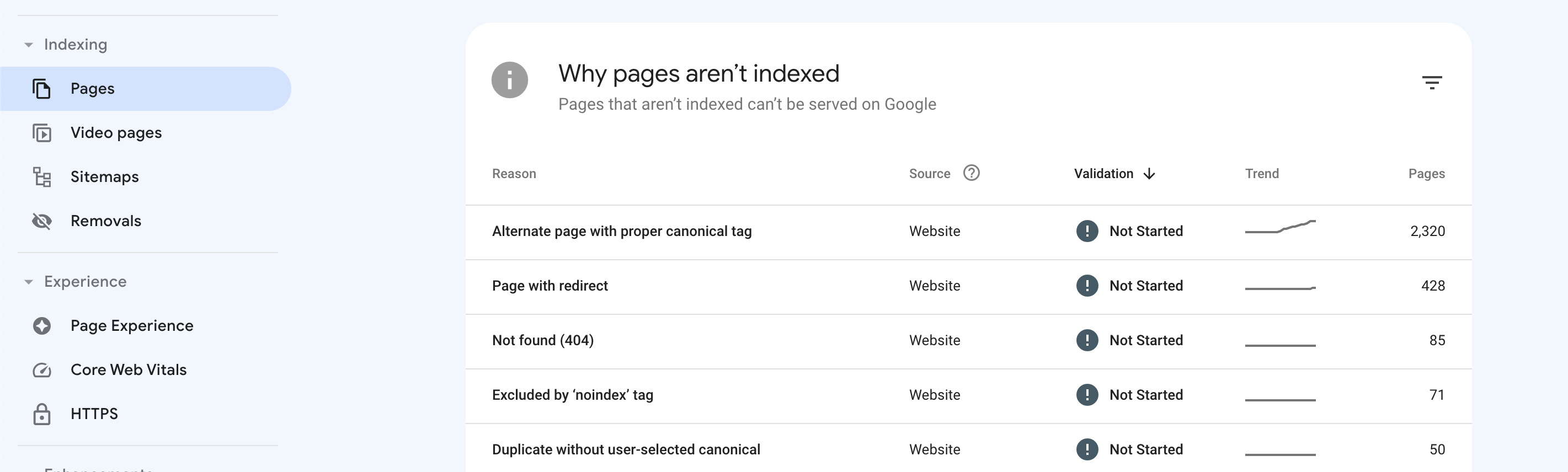
Specifically, look out for the following reasons that point to canonicalization issues:
- Alternate page with proper canonical tag: The non-indexed page has a canonical tag leading to the main version and was, therefore, ignored.
- Duplicate without user-selected canonical: Google's crawlers found duplicate content on multiple pages, and you have to specify the canonical version.
- Duplicate, Google chose different canonical than user: Google has selected a different URL as the canonical version of a page than the one specified.
If you wish to check a specific page, then use the URL inspection tool to see whether the page is indexed or not.

For a quick spot-check on any individual page, you can also open your browser's DevTools (right-click > Inspect > Elements), search the head section for "canonical," and verify the tag points to the URL you expect.
For larger sites, a dedicated site crawler like Screaming Frog's SEO Spider can simulate Google's indexing process and flag canonicalization issues across hundreds or thousands of pages at once. This is more efficient than checking pages one by one in GSC.
Once your canonical tags are technically correct, it also helps to verify that your canonical pages have strong, comprehensive content. A page with thin content is more likely to have its canonical overridden by Google in favor of a more authoritative version. Tools like Surfer's Content Editor can help you assess topical coverage and ensure your canonical pages send the right quality signals.
6 common canonicalization issues and how to fix them
Even if you follow all of the above canonicalization best practices, Google might still ignore your canonical link due to seemingly unrelated problems. Let's dive into the most common ones and their solutions.
Language variants without localized annotations
If you offer the same or similar content in multiple languages, Google might see this as duplication.
This is especially true for pages with several variants of the same language, where you might only change the spelling, such as British vs. American English.
Even if the languages are entirely different, remember that Google indexes URLs, not the actual page contents. To avoid duplicate content, you must use localized annotations by adding another tag—hreflang.
Let's assume your English printables website is translated into French and Italian. In this case, your hreflang tags would look like this:

In the above syntax, rel="alternate" suggests that this is the alternate version of the page, and the hreflang tag explains why.
So why does one page include all three language variants?
There are two reasons for this:
- Hreflang tags are bidirectional, which means that if one page leads to another variant, that variant needs to lead back to it as well.
- Google highly recommends using self-referencing hreflang tags
With this in mind, each page must include a hreflang tag leading to itself and all alternate language variants.
Similar to canonical tags, hreflang tags can be implemented in three ways:
- Adding a tag to the head section of the page's HTML
- Including it in the HTTP header
- Adding it to the sitemap
Incorrect canonical elements
As mentioned, modern content management systems simplify canonicalization by letting you copy/paste your preferred canonical URL in the dedicated section.
Unfortunately, they might sometimes use improper techniques for setting the canonical tag, rendering it ineffective. This is one of the most common canonical tag errors you might face when working with a CMS, and it can be quite frustrating.
If your preferred URL isn't set as the canonical version despite following the necessary steps in your CMS, you should inspect the page's HTML to check whether the tag structure is correct.
While you might be able to fix any errors you notice independently, it's best to contact your CMS provider to notify them of the issue so that they can prevent it from happening again.
Misconfigured servers
Not all canonicalization issues are under your control. Sometimes, indexing problems can happen due to server misconfiguration.
In this case, you might notice the following errors:
- A canonical page points to a 5XX HTTP status code, which signifies server problems and makes the page inaccessible.
- The server is returning content from a different domain.
- Different servers return the same soft 404 pages, which means the request was fulfilled but the page is actually empty or missing.
In any of the above situations, you should contact your hosting provider to resolve these misconfigurations.
Malicious hacking
Canonicalization issues can also happen as a result of your website falling victim to a cyberattack. For example, a hacker might inject code that involves 3XX redirects or cross-domain canonical annotations that lead to spammy or malicious URLs.
Google's crawlers would still follow these signals, so they might prioritize the malicious URL over the affected one. If you believe this has happened, contact a cybersecurity expert for help.
Syndicated content
If you syndicate your content to many other websites, it can be hard for Google to determine the original version of your piece. A canonical link element won't do much here because the pages your content is on are significantly different.
There are two main approaches to handle this. First, you can ask syndication partners to use a cross-domain canonical tag that points back to your original URL. This tells Google that the syndicated copy is a duplicate and your page is the source:
<link rel="canonical" href="https://yourdomain.com/original-article" />
Second, if a cross-domain canonical isn't practical, you can ask syndication partners to block Google's bots from indexing your content on their website. They can do so by using the following robots meta tag:

A copycat website
While Google is typically good at weeding out copied content, its algorithm isn't perfect. In some cases, a web page containing stolen content might be chosen as the canonical version.
If this happens, the best thing to do is use Google's Legal Troubleshooter to file an infringement report.
Note that you may be liable for considerable damages if you misinterpret someone's content as stolen, so make sure you can prove the infringement.
Make every canonical tag count
Canonical tags are a small piece of HTML with an outsized impact on how search engines treat your site. They protect your crawl budget, consolidate link equity, and ensure the right pages appear in search results.
The fundamentals are straightforward: use absolute URLs, stick to HTTPS, keep one canonical per page, and make sure every signal (internal links, sitemaps, redirects) points to the same preferred URL. If you're running a JavaScript framework, pay close attention to how your canonical tags render.
If you haven't audited your canonical setup recently, start with Google Search Console's indexing reports. Look for pages flagged as duplicates or cases where Google chose a different canonical than the one you specified. Fix those first, and you should see indexing improvements within a few weeks.



