
It seems reasonable to assume that stronger domains have a higher chance of being cited in AI answers. But is that actually true or just a hangover assumption from the “ten blue links” era?
To find out, we pulled three months of AI Tracker data from Surfer spanning 20,000 prompts and ~5 million unique citation source URLs across AI Mode, AI Overviews, ChatGPT, and Perplexity.
We then measured how citation likelihood correlates with three different domain authority metrics: PageRank and Harmonic Centrality from Common Crawl and Domain Score from Surfer via DataForSEO.
Result?
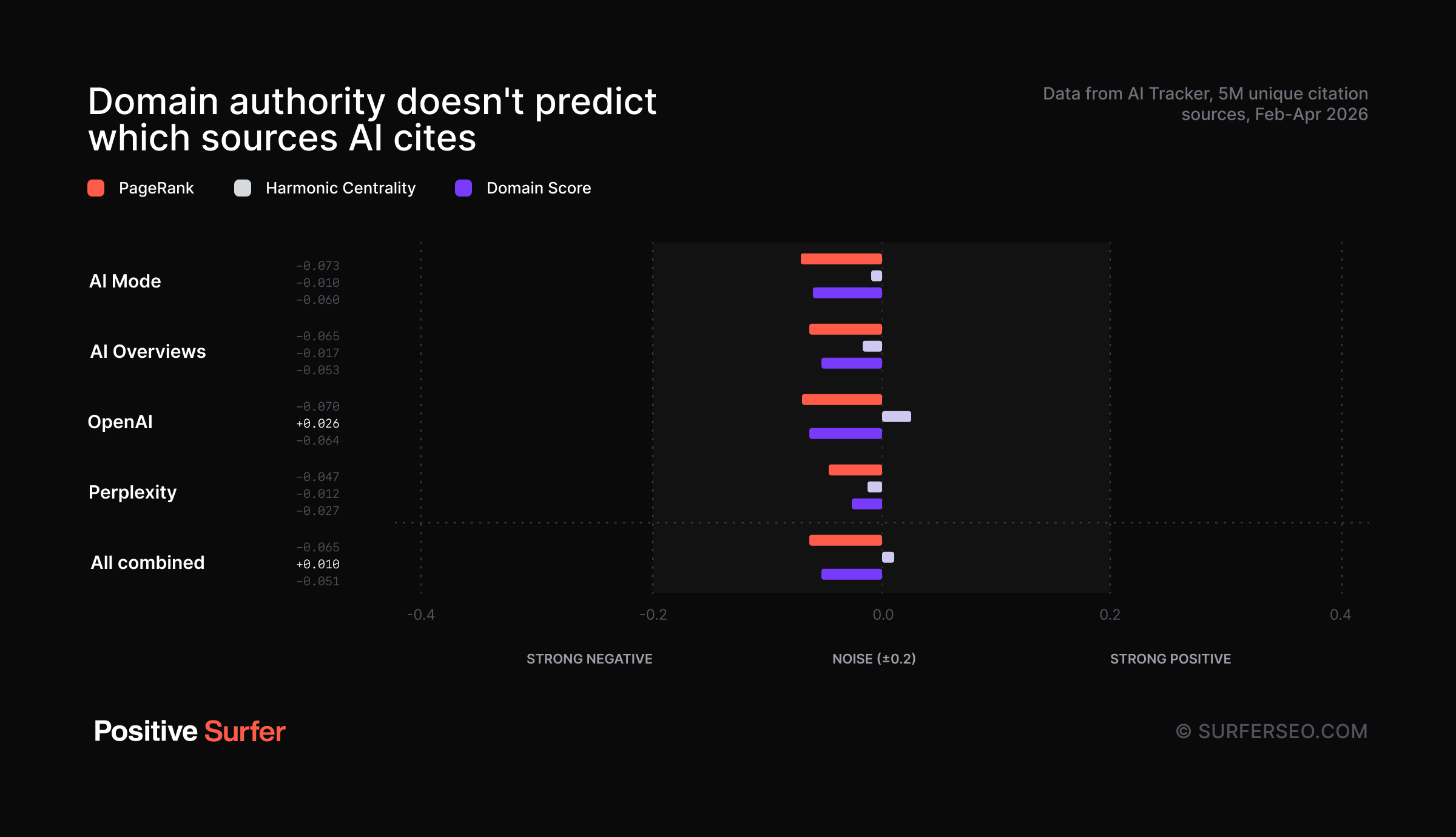
Domain authority correlates negatively with AI citation frequency—but barely. It's close enough to zero to be noise.
Quick definitions, in case these terms are new:
PageRank measures how important a page is based on who links to it. The classic Google-era idea: a link is a vote, and votes from already-important pages count for more than votes from obscure ones. A page with lots of high-quality links pointing at it gets a high PageRank.
Harmonic Centrality measures how well-connected a domain is within the "web graph" (the whole internet modeled as pages connected by links). A high score means you can reach the domain in very few link-hops from almost anywhere on the web, so it sits near the center of everything, like Wikipedia or Reddit. A low score means it's tucked away on the periphery.
Domain Score is Surfer's overall domain-strength metric (similar in spirit to "domain authority" scores you may have seen elsewhere), combining link signals into a single 0 to 100 rating.
All three are different ways of answering the same basic question: how strong or authoritative is this domain? That's exactly the assumption we set out to test.
Here are the raw Spearman correlations (I know they're a bit hard to see on the graph):
But what happens when you slice the data a bit further? Does anything change? And what does it actually mean for your AI search strategy (GEO, AEO, LLMO, EIEIO, whatever we're calling it this week)?
Let’s dig a bit deeper.
Before we continue: a quick note on the data
All the data in this post uses subsampled data.
What does this mean? It means we split all sources into 20 equal buckets based on how frequently they appeared in answers, then sampled one source from each bucket.
Why did we do this? To help us make sure we remove one potential source of error. You see, we noticed that there are a handful of core sources that show up in AI answers constantly, and a long tail of sources that show up rarely. Running a straight correlation across that imbalanced distribution means the the most cited sources dominate the results and skew everything. Using subsampling means every tier of citation frequency gets equal weight in the correlation.
That said, the results between subsampled and non-subsampled data were similar.
A few strong domains seem to be almost entirely responsible for the slight negative correlation
It seems plausible that domain authority doesn’t strongly predict AI citation frequency. But a negative relationship? That feels strange.
Our theory was that this may come down to well-known publishers like Reddit and Wikipedia being massively over-represented in the dataset. These sites get to the AI answer source selection stage way more often than others because they cover nearly all topics and rank in the index very well. As a result, the LLM will frequently see them as candidates for being cited.
But this alone doesn't explain the negative correlation.
There seems to be some kind of regularization applied by AI search engine engineers to deprioritize these domains since their domination doesn't necessarily come with the best answers.
To test this, we removed the top 5% of the strongest domains from the dataset entirely and re-ran the correlation.
Result? The slight negative correlations largely disappeared, collapsing even closer toward zero across all four AI models and all three authority metrics.
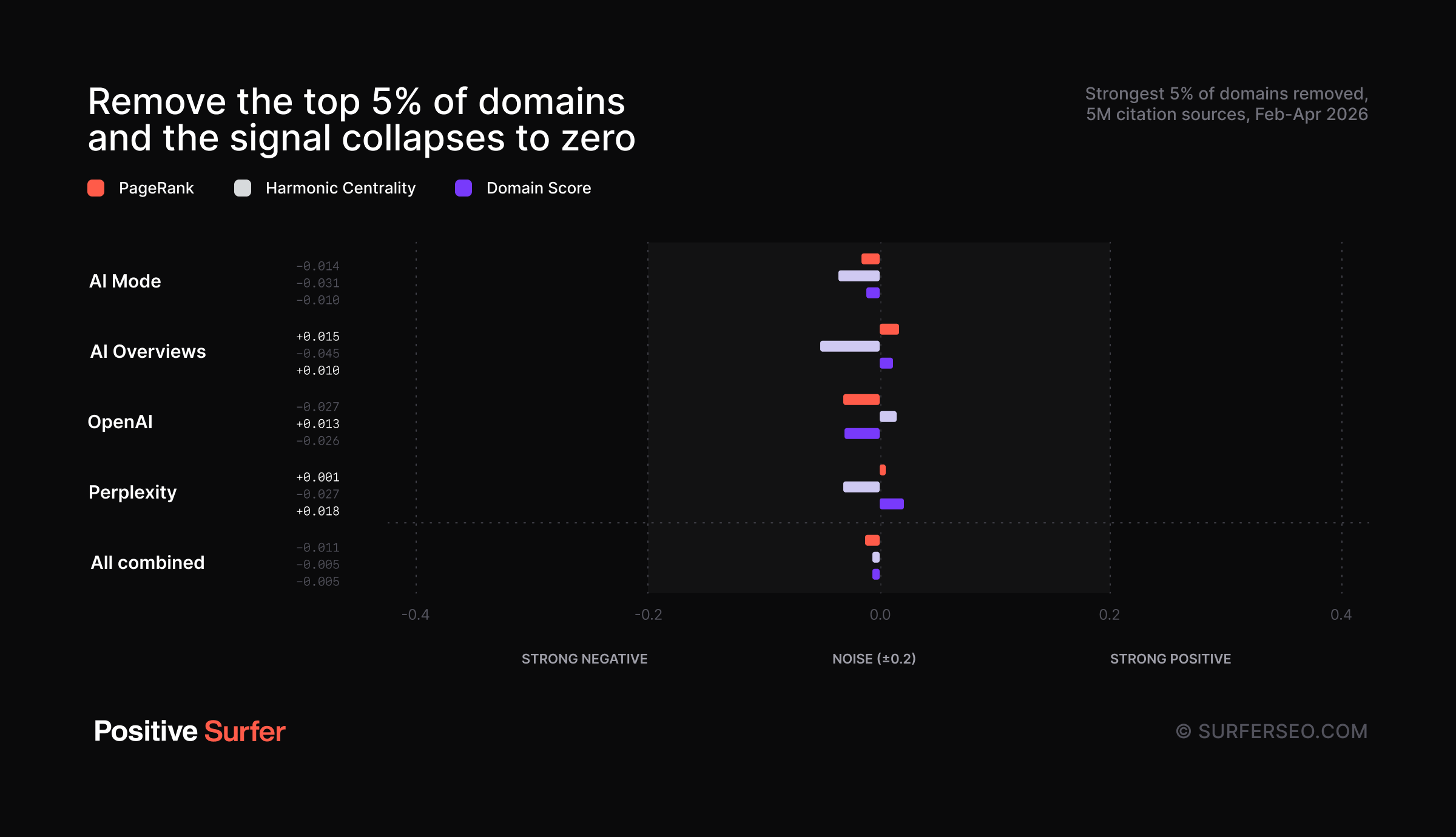
Here are the raw Spearman correlations with the top 5% removed:
As we theorized, this seems to suggest that AI answer engines may be actively deprioritising the strongest domains—possibly to diversify sources, avoid over-reliance on a handful of mega-publishers, or both.
However, another explanation is simply that the strongest domains publish citable content far less frequently than weaker ones. That obviously doesn’t apply to sites like Wikipedia, but you can see how it might apply to platforms like X (Twitter), which increasingly seem to be home to divisive nonsense rather than genuinely useful information.
Either way, Perplexity appears to be slightly less aggressive about deprioritising strong domains whatever is going on here than the other models. But even Perplexity doesn't seem to be actively rewarding authority.
Filtering for blog posts nudges the correlations ever so slightly positive
We also filtered the dataset down to blog posts only—specifically URLs containing /blog/. (That’s obviously far from a perfect proxy, but it should cover most of them).
Result? The correlations nudge ever so slightly positive across most models and metrics—but with one glaring exception.
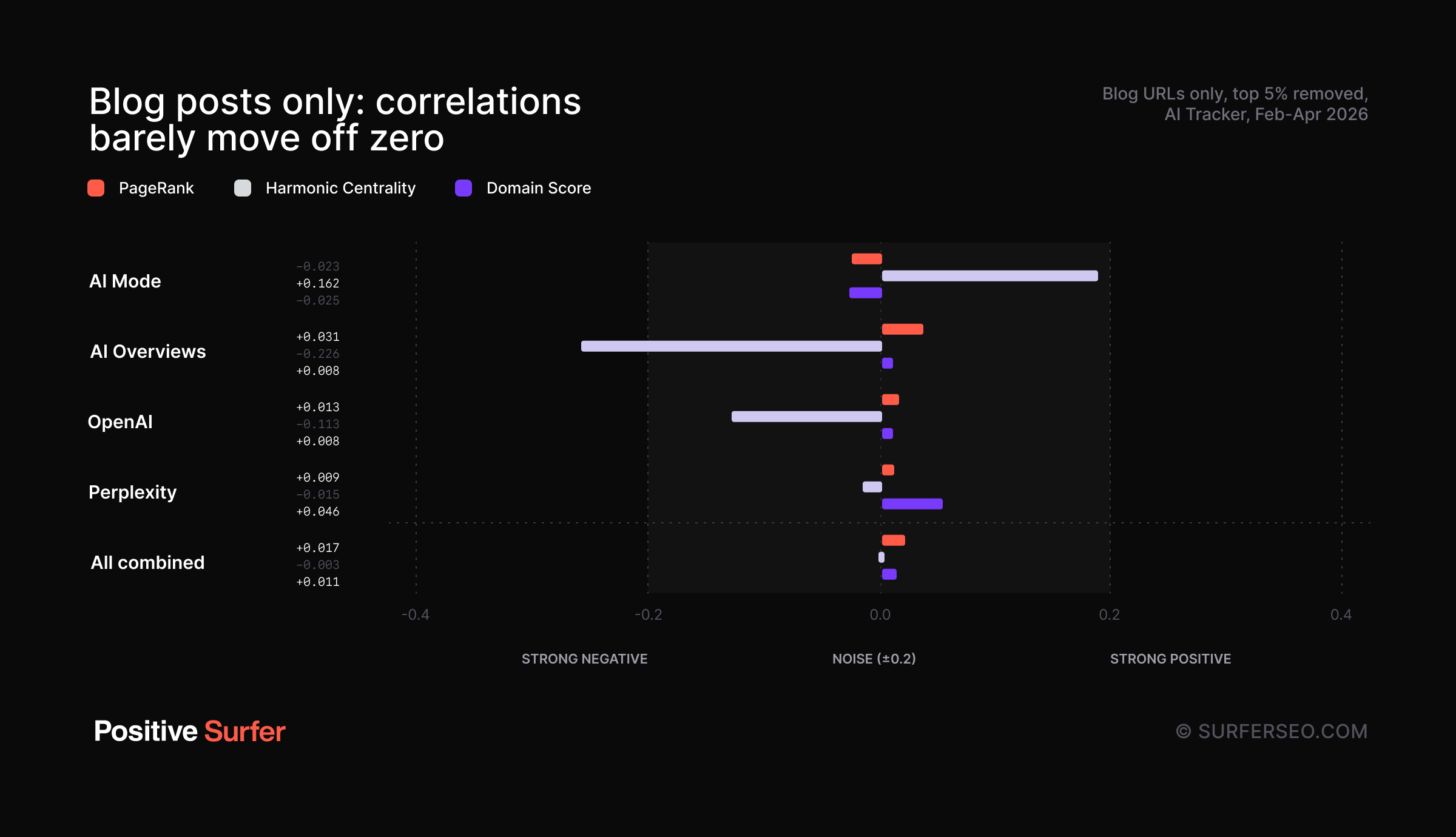
Here are the raw correlations:
NOTE. This data still has the top 5% of domains removed.
While PageRank and Domain Score essentially flatline into complete noise, Harmonic Centrality (HC) goes on a bit of a rollercoaster ride. It jumps to a mild positive correlation (+0.162) in AI Mode, but tanks into a sharper negative correlation (-0.226) for AI Overviews.
So… what’s going on here?
I asked our data scientist, Maciej Gruszczyński, about this, and he pointed out an important and fascinating nuance about how LLMs are actually built that might explain the chaos.
Basically, it's common knowledge in data science circles that the Common Crawl Bot prioritizes its web scraping by Harmonic Centrality. That means domains with higher HC are crawled more heavily, which results in them being much better represented in the massive datasets used to train these LLMs in the first place. And if you're baked into the foundational knowledge of the model, you're inherently a strong candidate to be surfaced.
But even when you remove massive multi-topic sites like Wikipedia or Reddit and filter down to /blog/ URLs, you're still left with two very different groups: niche blogs and general blogs.
General blogs touch on a massive variety of topics, which naturally gives them a higher Harmonic Centrality score and deeper representation in LLM training data. Niche blogs keep it tight and hyper-focused.
As Maciej puts it:
"I can't explain why it's so positive or so negative for different models. It would be too much of a coffee-ground telling, but definitely the two factors I described (bot prioritization and niche vs general blogs) can play a significant role."
But technical rabbit holes and wild HC swings aside, take a look at what happened to PageRank and Domain Score. While they are both still hovering incredibly close to the zero line, filtering for blog posts did manage to nudge them into slightly positive territory across almost model.
Does this mean that blog posts carry some inherent weight in AI search engines regardless of domain authority?
It’s an interesting theory, and one that would align with the findings from our previous study on brand presence and AI recommendations. That study found that mentions in blog posts correlate more strongly with recommendation strength than any other content type, despite blogs accounting for just 28.7% of cited sources overall.
But given how much the HC metrics swing between positive and negative depending on the model, I'd still be cautious about drawing definitive conclusions here. The big picture hasn't changed: traditional metrics are no longer a golden ticket.
So what does all this mean for AI search, and what should you do about it?
Domain authority doesn't appear to have any meaningful impact on the likelihood of being cited by AI search engines. That's the takeaway.
Of course, this doesn't mean off-page factors are irrelevant to AI search entirely. There are plenty of other signals we didn't measure, and some of them may well matter.
But the studies I’ve seen so far, including this one, point consistently in the same direction: traditional link-based authority metrics appear to be much weaker predictors of success in AI search than in traditional search.
And if authority matters less, the natural conclusion is that content likely matters more.
And that’s good news. Because unlike authority, content is something that anyone can compete on.
But how do you create content that’s genuinely competitive and stands the best chance of getting cited by AI and ranking in traditional search?
I think this quote from a recent post by Gianluca Fiorelli summarises it nicely:
"The winning position — for both traditional rankings and AI citations — is content anchored in established consensus that simultaneously contributes genuine new information."
— Gianluca Fiorelli
Surfer's new Content Editor workflow is built around exactly this idea.
For example, say I enter "link building tips" as my topic. Surfer first does deep research across ChatGPT, AI Overviews, Gemini, AI Mode, Perplexity, and the first page of Google to figure out what actually matters: the key entities, subtopics, facts, and information you need to cover as a baseline to stand any real chance in both traditional search and AI answers.
It then recommends the best content format based on the research.
Then (and this is the most important part, in my opinion) it asks for additional context and instructions. This is where you add the things that make your content genuinely stand out: original research, strong opinions, proprietary data, expert quotes, etc.
In my case I fed it a bunch of quotes I collected from some seriously smart SEOs and told it to weave them throughout.
From there it generates the content in your voice, with all of that original material baked in. And the results are… well, pretty damn good (see below).
(Prefer to write from scratch and only use AI assistance if you need to? You can do that too.)
You can see it included the quotes I fed it contextually within tips that actually make sense. It also optimized my post for all the boring stuff in the background, as you can see from the 93/100 Content Score.
What I love about this is that it frees up my time for the fun parts of content creation (developing a unique opinion, conducting research, sourcing original insights) while handling the optimization and bulk of the writing for me.
Does it still need a bit of editing? Of course. But so does any first draft—especially if I'm the one writing it!
Want to see what it does with your topic? Give Content Editor a try for free.



