
"Content ideas can come from various sources. This time it was the Chiang Mai SEO conference. One of the attendees, Felix Norton from Woww approached me after I finished my talk and asked,..."
"What is the real difference between scraping AI results and using APIs to request answers from LLMs?”
I said, "Well, yes there is a difference, we are scraping…" but he insisted, "For real, how big is it? What makes it different?”
I lowered my voice to admit that I do not know specifically but promised him that I would test it.
Later that evening, we met again and sent a lengthy scope to the data science team at Surfer to test it.
Three weeks later, we have results broken down by Jakub Sadowski and Wojciech Korczyński.
This introduction is written for you. Not for AI bots.
What is the difference here? AI does not like sidetracks, anecdotes, and engaging sentences that build the story (actually real). I hope you do; it makes a connection between the reader and the author.
If you are curious about this topic, we are writing another study on LLM ranking factors that will cover it.
Read on to find out what the difference is between using an API to source AI generated answers, and scraping actual AI answers.
Thanks Michał! We’ll take it from here…
Understanding data collection methods for AI platforms
Let’s clear up one big misconception right away: there is no “ChatGPT API.”
What we do have are APIs for specific models such as GPT-5 or GPT-5.1-mini. These are the brains behind ChatGPT—but they are not ChatGPT itself.
The same goes for Perplexity. There’s no “Perplexity API” that behaves exactly like the web interface.
You only get access to underlying models like Sonar, Sonar Pro, or Sonar Reasoning.
OpenAI API vs. ChatGPT: What’s the difference?
Think of the API as the raw model.
Think of ChatGPT as the raw model plus:
- special instructions (system prompts),
- extra data feeds,
- interface logic,
- small secret adjustments only OpenAI knows about.
Because of these layers, ChatGPT behaves differently from the API—even when they use the exact same model.
Web scraping: capturing the real user experience
Web scraping collects the exact output shown in the ChatGPT or Perplexity interface.
This includes:
- the final message shown to the user
- formatting
- interactive UI elements
- sources
- and all the extra logic layered on top of the model.
Scraping shows you what real people actually see.
API Access
API-based data collection, on the other hand, gives you structured, programmatic access through official endpoints.
APIs give you:
- clean, structured responses,
- function-calling,
- consistent formats.
But they do not include the interface logic, search behavior, sources, or the “extra magic” platforms apply when responding to users.
So for building apps?
API = great.
For monitoring how your brand appears in the AI tools people actually use?
API = not great.
What is the difference between scraping LLM answers and API data?
Ok—it sounds like scraped results are better for brand monitoring and AI search optimization. But the big question remains:
What is the actual difference?
We tested two scenarios, running 1,000 prompt executions each time.
First, we compared scraped results with a “clean” API.
Second, we added a twist: we used a leaked OpenAI system prompt from GitHub.
The results were nearly identical in both cases, with and without the system prompt.
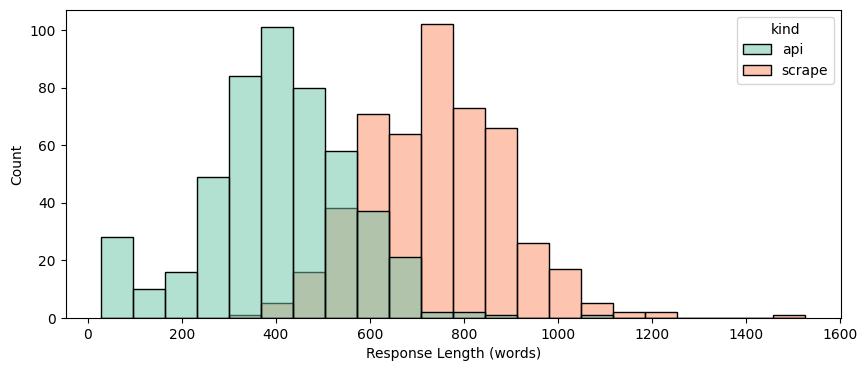
Here’s what we found,
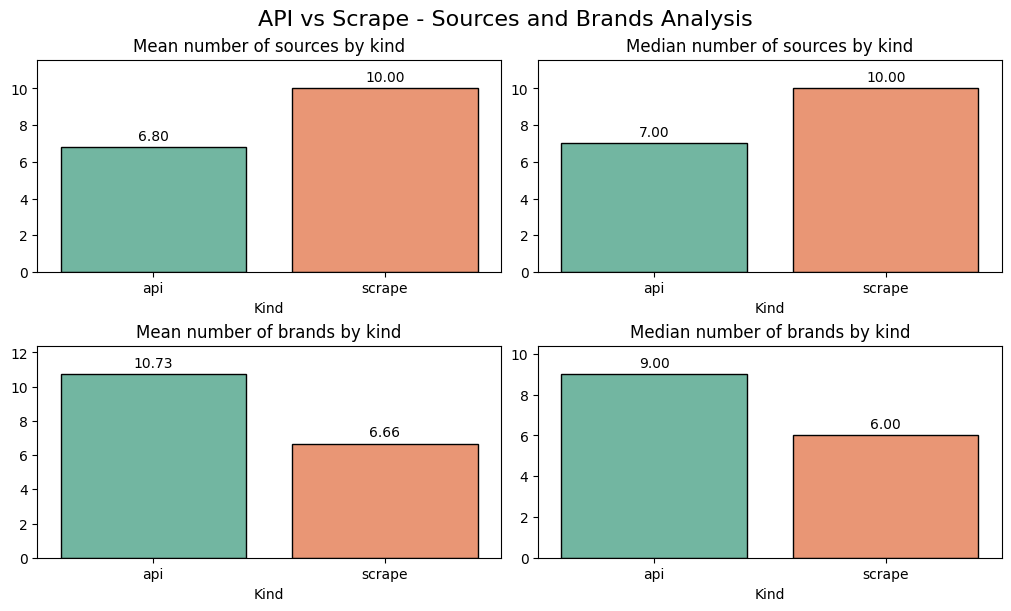
Length:
API responses are much shorter (avg. 406 words) than scraped responses (avg. 743 words).
Web Search:
~23% of API responses do not trigger web search (usually when under 100 words). Scraped results always trigger web searches.
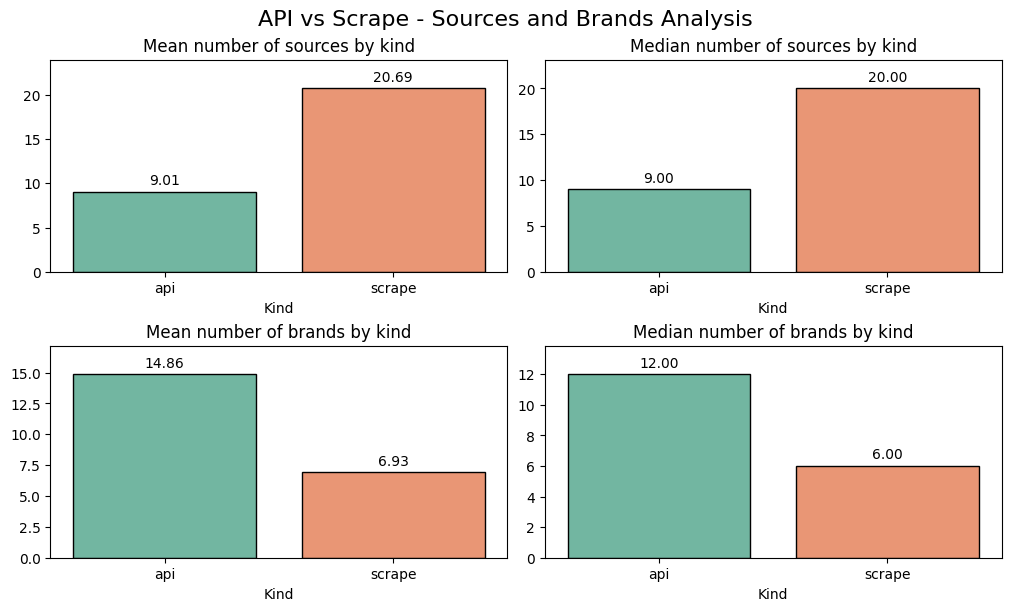
Sources:
APIs provide no sources in ~25% of cases. Scraped AI answers always provide sources, and about twice as many (16 vs. 7 on average).
Brand Detection:
The API sourced data fails to detect any brands ~8% of the time while scraped answers always identify brands.
When brands are detected, APIs identify more on average (12 vs. 9).
The big question: are API results and ChatGPT results the same?
From an AI search monitoring perspective, the key question is:
Will I get the same results from the API as from the web/app interface?
No. Absolutely not.
Here’s how different they are:
- Only 24% of brands overlap between API and scraped results.
- For sources, the overlap is just 4%.
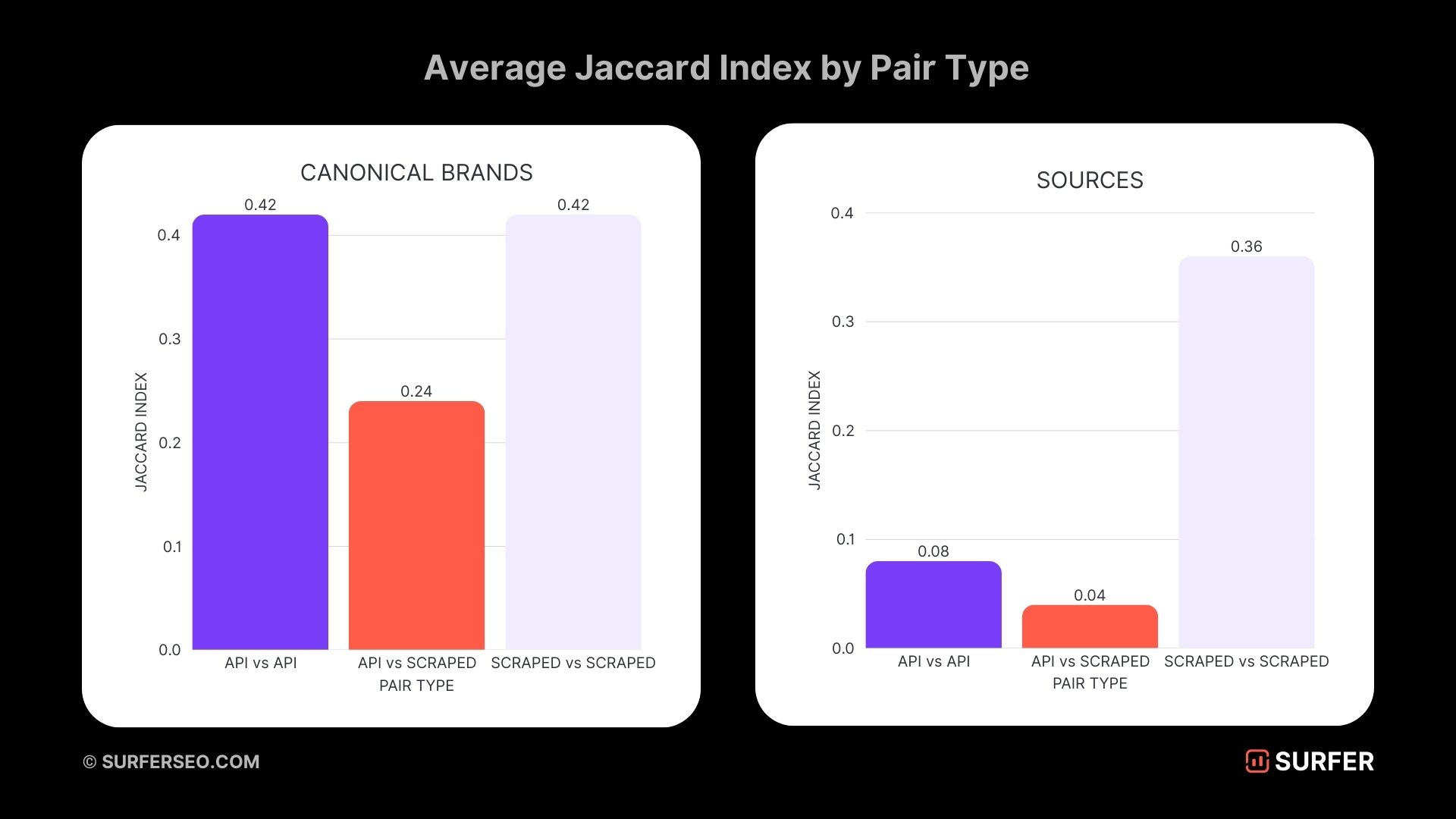
This means:
- If you use API-based sources to optimize for ChatGPT, you’re optimizing for the wrong thing.
- You’ll assume certain sources matter—when they don’t appear in real ChatGPT results at all.
“These results confirm that API responses differ very strongly from scraped responses in the LLM. These differences are so explicit that monitoring responses from API as a proxy for your AI visibility is totally wrong.”
— Wojciech Korczyński, Data Scientist @ Surfer
We could stop here. But at Surfer, we go the extra mile.
So we ran the same test for:
Perplexity user results vs. Perplexity API results
Using the same test setup and prompt list, we found differences very similar to the ChatGPT results.
Length:
API responses are shorter (avg. 332 words) vs. scraped (avg. 433 words).
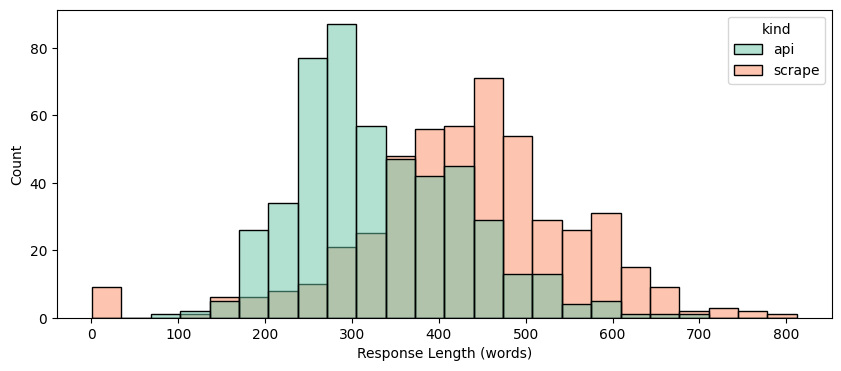
Web Search:
Both use web search consistently, but the API sometimes misses sources — resulting in no response at all.
Sources:
APIs return ~7 sources; scraped results always include 10.
Brand Mentions:
In ~5% of scraped responses, brand names are omitted in favor of more generic descriptions.
API responses typically include 10+ brands, while scraped responses average around 6.
And again, the critical part:
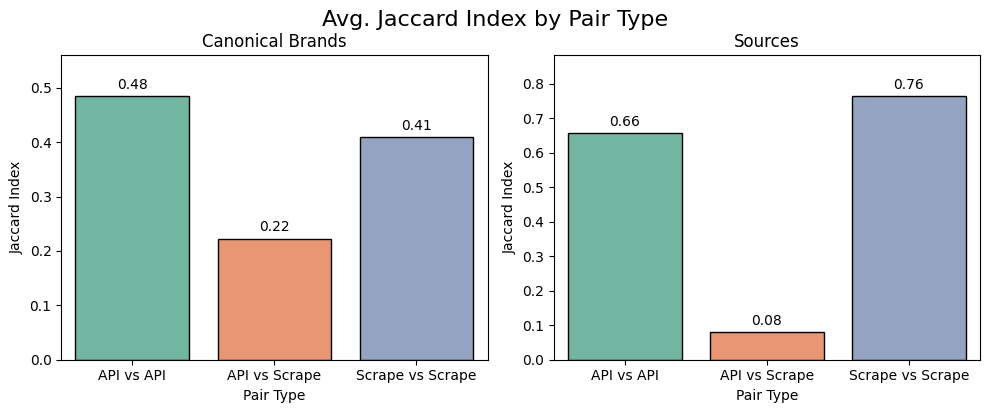
Are the brands and sources similar in Perplexity?
Yet again: NO.
Source overlap is just 8%, meaning the API and UI often pull from entirely different references.
API-based monitoring simply does not reflect what people actually see.
Use reliable tools to track AI visibility
If you want to measure how your brand appears in AI tools real people use, you must rely on the web interface, not the API.
Scraped data shows the truth.
APIs show structured, clean data that does not reflect real-world user experience.
Good monitoring tools — like Surfer’s AI Tracker—rely on high-quality scraped data because it captures what users actually see in platforms like ChatGPT and Perplexity.
If your data is wrong, your optimization strategy will be wrong too.
Good data is only the first step toward improving AI visibility. At Surfer, we know that. That’s why we never cut corners. We dig deep, test thoroughly, and ensure both our data and our processing methods are rock solid.
This is how we build the best possible AI visibility monitoring and optimization tool.


