
AI search engines don't browse or list ten different blue links. They assemble an answer and decide which sources are safe enough to quote.
What’s interesting is that those sources aren’t always the ones ranking highest. Surfer’s analysis of Google’s AI Overviews shows that 67.82% of cited sources don’t rank in Google’s top 10 for the same query.
That’s because large language models don’t rank pages. They select passages, reuse evidence, and cite what helps them answer confidently.
If your content isn’t built for that selection process, it’s invisible, regardless of where it ranks.
In this blog, I’m breaking down how LLM citations actually work, and how to optimize your content to earn them.
How large language models select sources to cite
AI search engines pull from multiple sources, extract the passages that best answer a question, and cite only the pages those answers come from.
They don’t rank pages or evaluate content as a whole. They assemble answers from different sources and pages.
Large language models like ChatGPT, Perplexity, and Google’s AI Mode rely on a process known as retrieval-augmented generation (RAG). In simple terms, this is what happens behind the scenes:
- The user’s prompt is broken into several related sub-queries
- Each sub-query is searched independently across the web
- Relevant documents are retrieved
- Individual passages are evaluated for clarity, accuracy, and usefulness
- The final answer is generated using those passages, with citations attached
This is exactly what this Perplexity result shows.
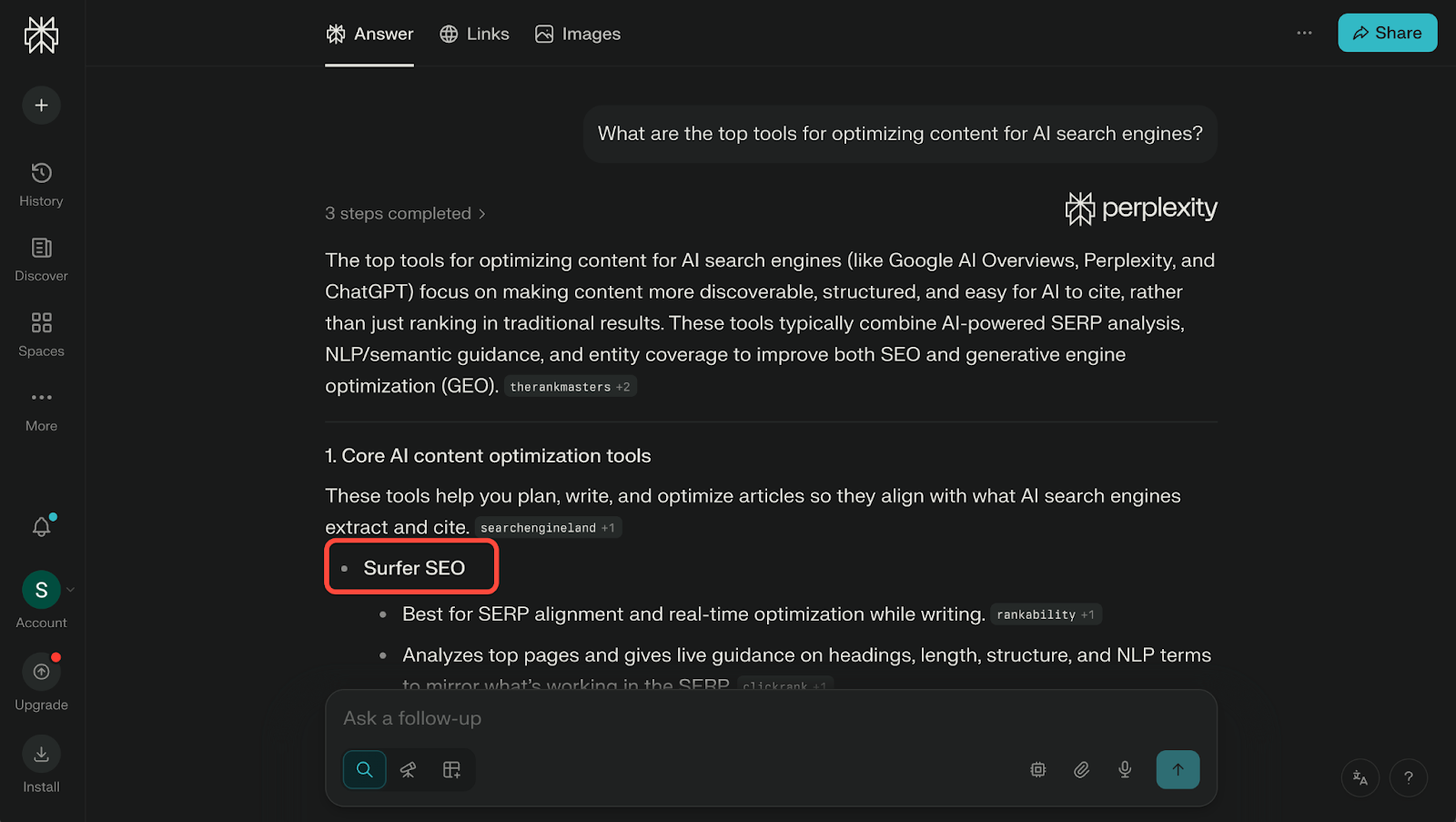
Perplexity pulls from a Search Engine Land source here, which has referenced Surfer in its analysis. This is because AI systems often inherit authority signals from human-trusted publications, especially when answering explanatory questions.
You’ll also notice that LLMs don’t cite pages directly. Instead, they cite passages.
A single paragraph, sentence, or definition can be cited if it clearly supports a specific response. The rest of the page may be ignored entirely. Traditional ranking position, overall page depth, or backlink strength are secondary to whether a passage helps the model answer confidently.
This explains two things that often surprise teams:
- Why pages outside Google’s top results still get cited
- Why long, well-written articles can be invisible in AI answers
If an answer is buried, vague, or wrapped in narrative, it’s harder for the model to extract. If it’s explicit, structured, and self-contained, it’s easier to reuse.
In short, optimizing for LLM citations is what helps create extractable answers that fit cleanly into how LLMs work.
How to earn LLM citations
Unlike traditional search, AI tools don’t rely on one domain. They assemble answers from multiple places, often prioritizing third-party platforms and aggregators that already concentrate trust, usage, or human validation. That’s why your website alone isn’t enough to win at AEO or GEO.
Here’s what you can do to diversify your approach for LLM citations:
1. Build presence beyond your own site
AI systems consistently pull citations from outside brand-owned domains, especially for comparative, subjective, or evaluative queries. That means, where your brand appears across the web often matters more than how well a single page is optimized.
But this pattern isn’t uniform. Different AI models favor different source types:
- A study from ConvertMate showed that ChatGPT answers lean toward traditional authority and rely heavily on major publications, Wikipedia, and human-centric platforms like Reddit.
- Perplexity tends to rely on community and experience-driven sources, with 46.7% of its top citations coming from Reddit, ~14% from YouTube, and a meaningful share from review platforms like G2, Yelp, and TripAdvisor.
At first glance, all this makes it easy to overestimate the role of forums like Reddit. But here’s what’s actually happening:
A Yext analysis of 6.8 million AI citations shows that most citations come from brand-controlled sources, not forums. First-party websites and business listings account for 86% of citations, while Reddit represents just 2% when intent and location are considered.
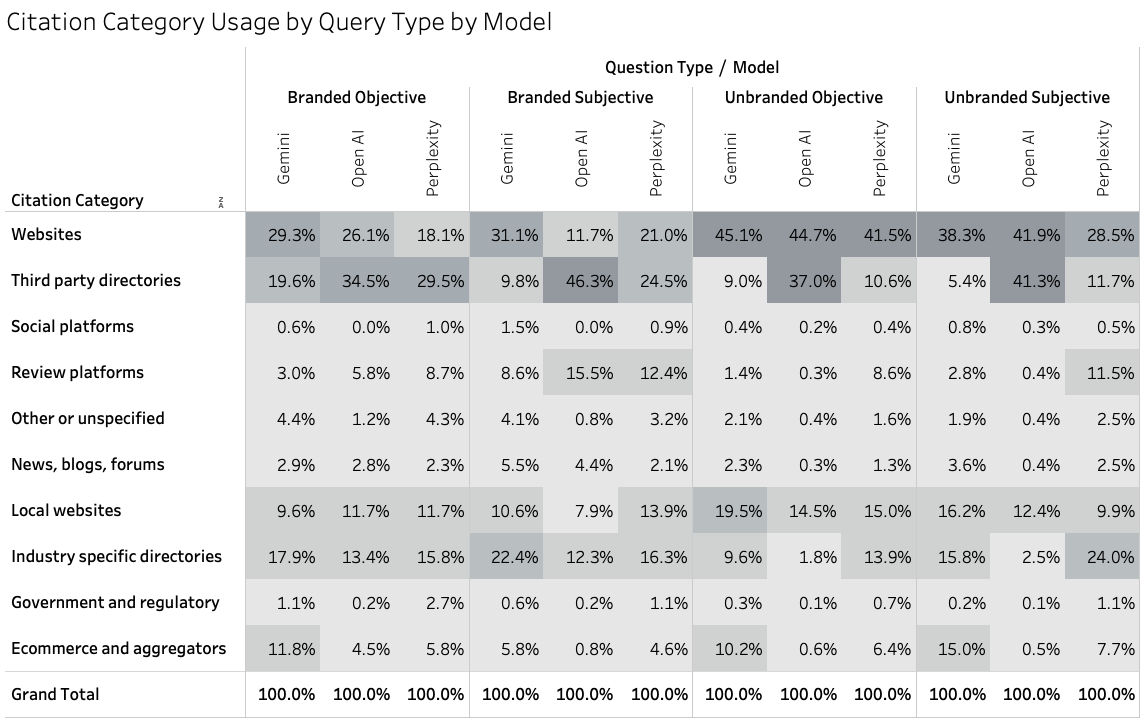
The reason isn’t contradictory. It’s contextual.
When users ask objective questions like tool pricing, availability, and specifications, AI systems overwhelmingly rely on brand-controlled internet sources and official listings.
But when users ask subjective questions like comparisons, recommendations, opinions, models shift toward community platform comments, reviews, and discussion forums.
This is why off-site presence matters.
For subjective and evaluative questions, authentic participation on Reddit plays a role (especially for Perplexity) because models reuse discussions that describe real opinions, edge cases, and lived experience.
And for explanatory queries, 14% of Perplexity citations come from YouTube. YouTube is also cited 200× more than any other video platform. Since AI models rely on transcripts, videos that clearly answer specific questions often become reusable source material.
For comparison and trust-based questions, review platforms act as validation layers.
Brands with active profiles on Trustpilot, G2, and Capterra have a 3× higher chance of being cited by ChatGPT because these platforms aggregate signals that AI systems use when assessing credibility.
In a way, this acts like digital PR that compounds over time.
Coverage in authoritative publications reinforces the sources AI models already rely on to explain how a topic works, increasing the likelihood of being cited across multiple prompts.
2. Keep pages fresh where freshness matters
For topics like pricing, tools, policies, and “best options,” AI systems are consistently biased toward updated sources because outdated information increases the risk of incorrect answers.
When information is likely to change, large language models are far less willing to reuse older content, even if it was once authoritative.
An Ahrefs study also found that AI assistants prefer content that is 25.7% fresher than URLs in organic search results.
This “freshness bias” is strongest on Perplexity.
A ConvertMate analysis found that freshness accounts for roughly 40% of Perplexity’s ranking factors, making it the single most influential signal for visibility on the platform.
Interestingly, the same study shows that content labeled as “updated two hours ago” was cited 38% more often than content that was a month old on identical topics. For evolving queries, Perplexity effectively assumes that older content is incomplete.
But this doesn’t mean every page needs an updated version.
For evergreen content styles (definitions, frameworks, or foundational explanations), AI models will still reuse older material if it’s accurate. Freshness only becomes critical when the question implies recency.
What doesn’t work is surface-level updating.
Changing a publish date or adding “updated today” without meaningful edits isn’t enough. If the underlying text hasn’t changed, AI systems can detect that mismatch and treat the page as stale anyway.
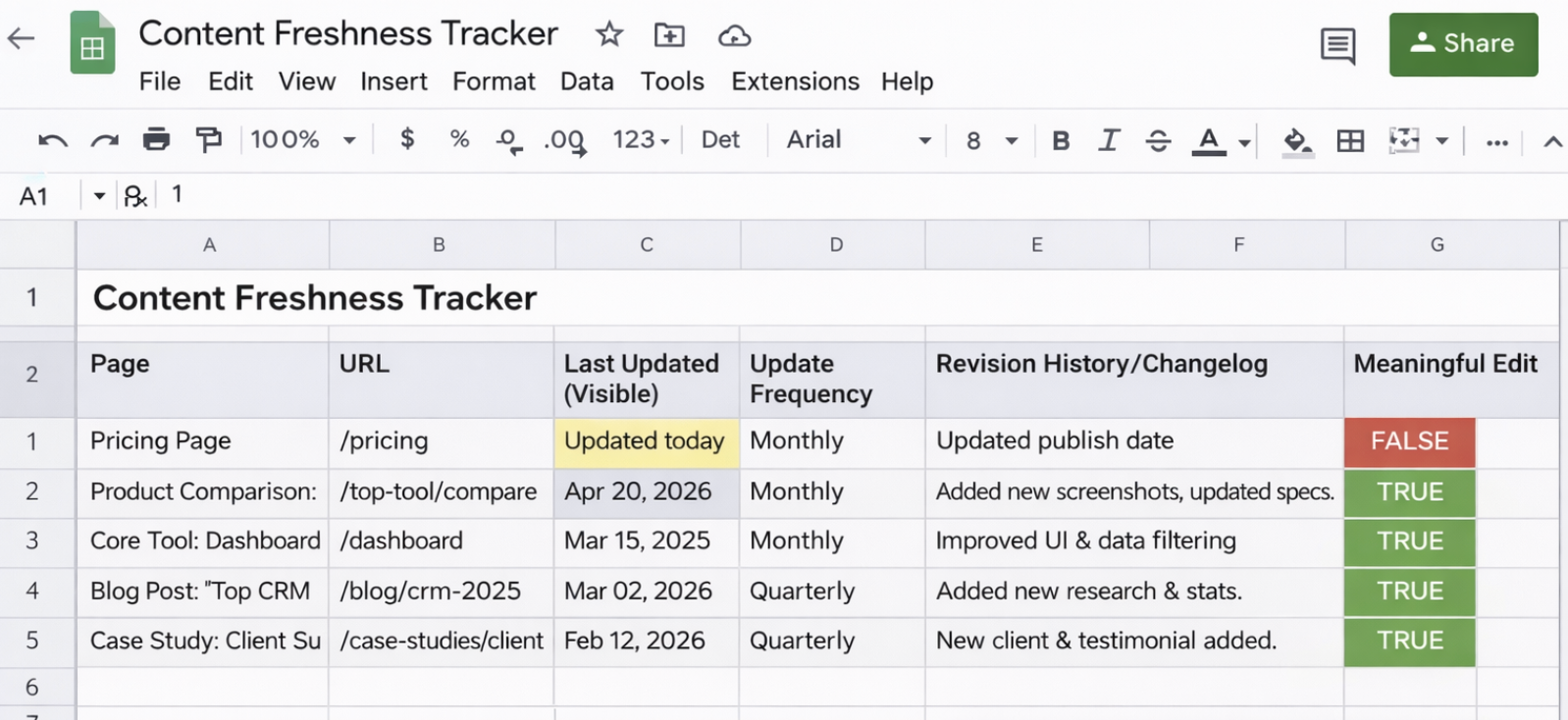
A more reliable approach is to:
- Identify critical pages (pricing, comparisons, core tool pages)
- Update them monthly or quarterly, or faster if the topic changes quickly
- Add a visible “Last updated” date near the top of the page
- Include a short revision history or changelog that explains what changed
Here’s a sample tracking sheet content teams can use to manage update cadence, visible dates, and meaningful revisions:
3. Add structured data (schema)
Large language models don’t read pages the way humans do.
They rely on structured signals to interpret intent, context, and credibility. The same research from Convertmate shows that proper schema implementation can deliver up to a 10% visibility boost on Perplexity, even though schema alone doesn’t force a citation.
Instead, it can help you with search visibility in blue-link results because we know that AI search engines use results from traditional search engines, at least in part, to generate their answers.
Schema helps reduce ambiguity by explicitly labeling elements like authorship, content type, update history, and entities, which makes your pages easier to retrieve and reuse during AI-generated responses.
As a best practice, use schema selectively and accurately, not applying everything by default. The most effective formats typically include:
- Article schema with clear author attribution and a visible dateModified
- FAQPage schema, but only when the page genuinely answers common questions
- HowTo schema for content with real, step-by-step instructions
- Organization or Person schema to establish brand or author identity
- Product or SoftwareApplication schema for tool, platform, or software pages
This layered approach helps AI systems connect your content to the right entity and query type, which matters when LLMs rely on structured data to disambiguate similar answers.
Sharp HealthCare is a great example of how this actually works.
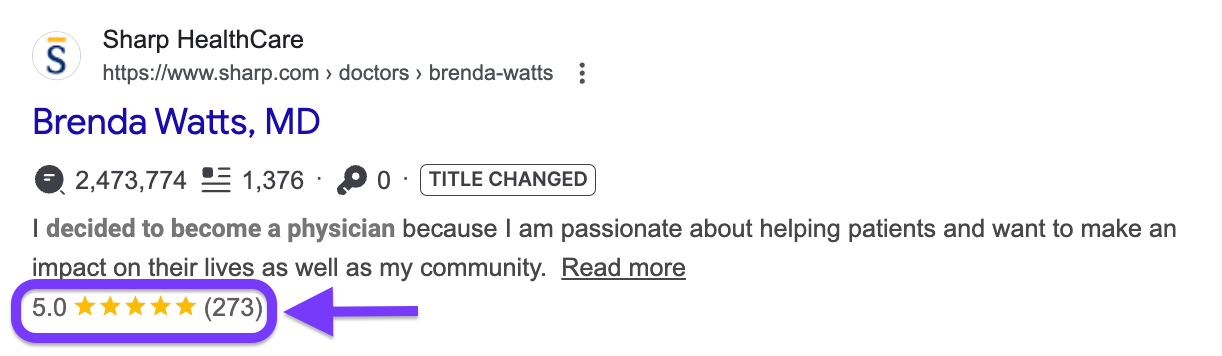
They implemented a comprehensive schema across their health content, including Article schema with physician authors, FAQ schema for common patient questions, and Organization schema tied to their medical credentials.
Within nine months, they saw an 843% increase in clicks from AI-generated search features, illustrating how structured data compounds visibility when paired with authoritative content.
Schema markup won’t guarantee citations, but it makes it significantly easier for other large language models to acknowledge what your content is about, who created it, when it was last updated, or its version.
4. Build topical depth to capture query fan-out
When AI search engines answer a question, they don’t search once and stop.
They break the original prompt into multiple sub-queries and search for answers to all of them simultaneously. This process is known as query fan-out.
You can see this using the Keyword Surfer extension inside ChatGPT. Here’s an example of the query fan-outs that ChatGPT generated when I searched for, “Should I use HubSpot for my startup?”
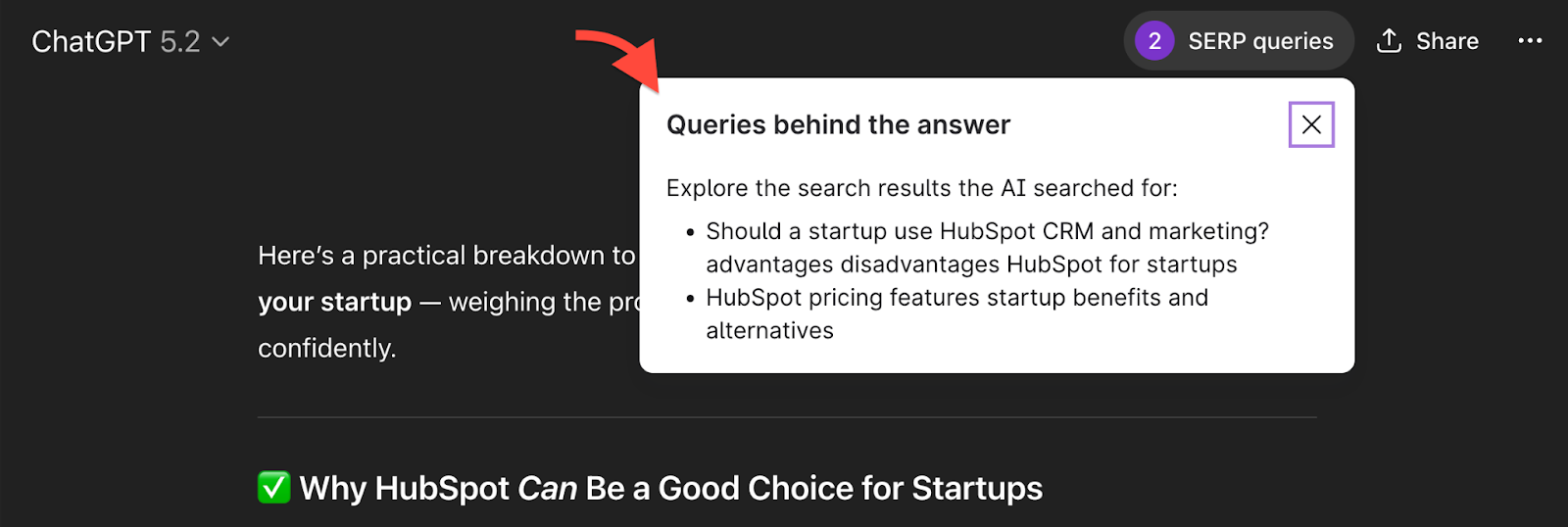
With a single prompt, you can see which fan-out queries were triggered by ChatGPT.
You can tell from the queries ChatGPT searched for, that it is trying to provide a well-rounded, complete answer that anticipates additional questions a potential buyer may have.
Like a human, it looks up the pros and cons of HubSpot for startups, and explores pricing and alternatives. Including information on these queries could add topical depth to your content and improve your chances of being cited as a ChatGPT response.
Another example you can see in action is through Google AI Mode.
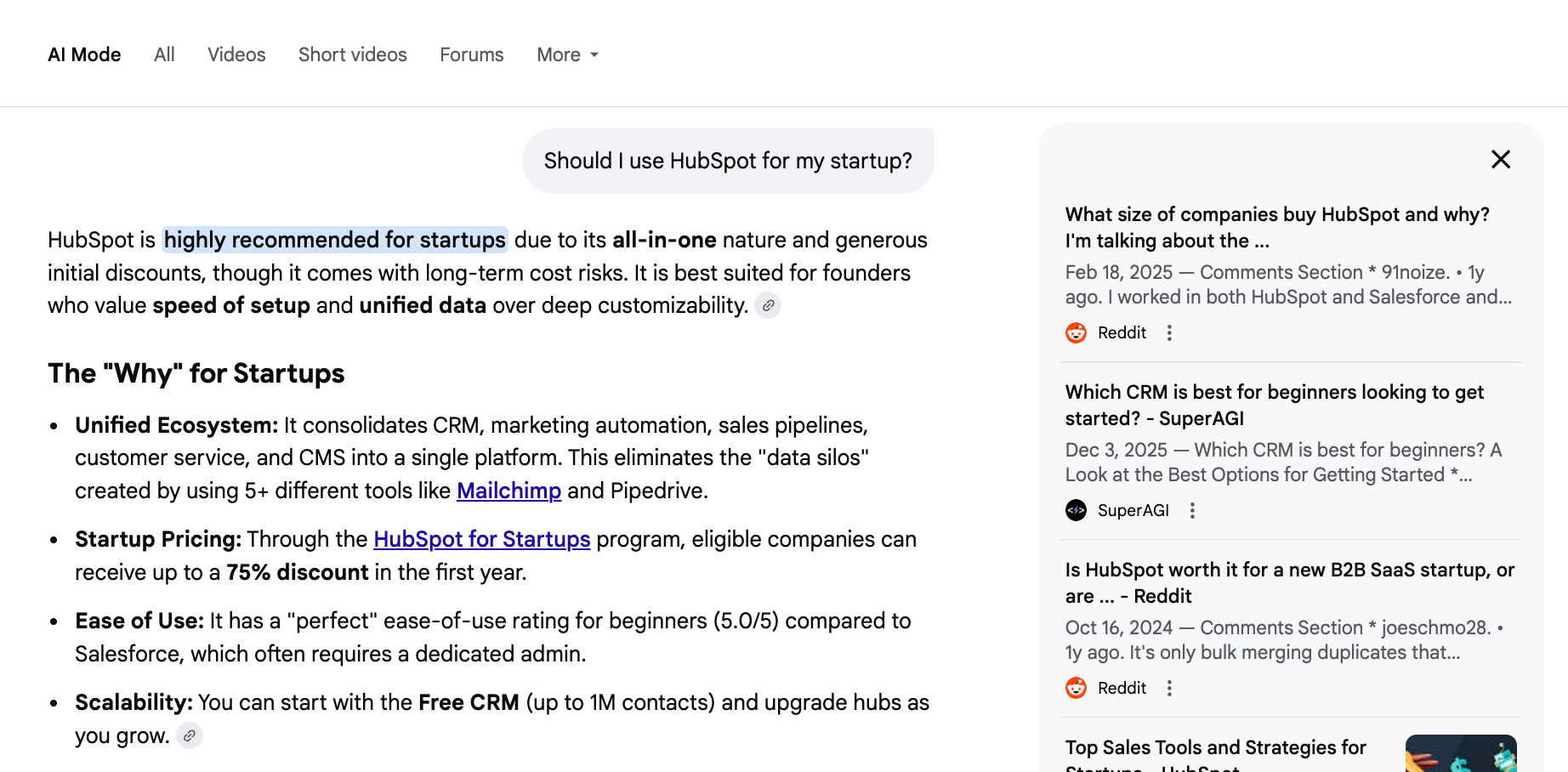
If you write something like "Should I use HubSpot for my startup?" the AI doesn't just search for that string alone.
It not-so-secretly fans out and searches for related queries like: "HubSpot Startup Pricing," "Drawbacks," and "Startup-Friendly Alternatives."
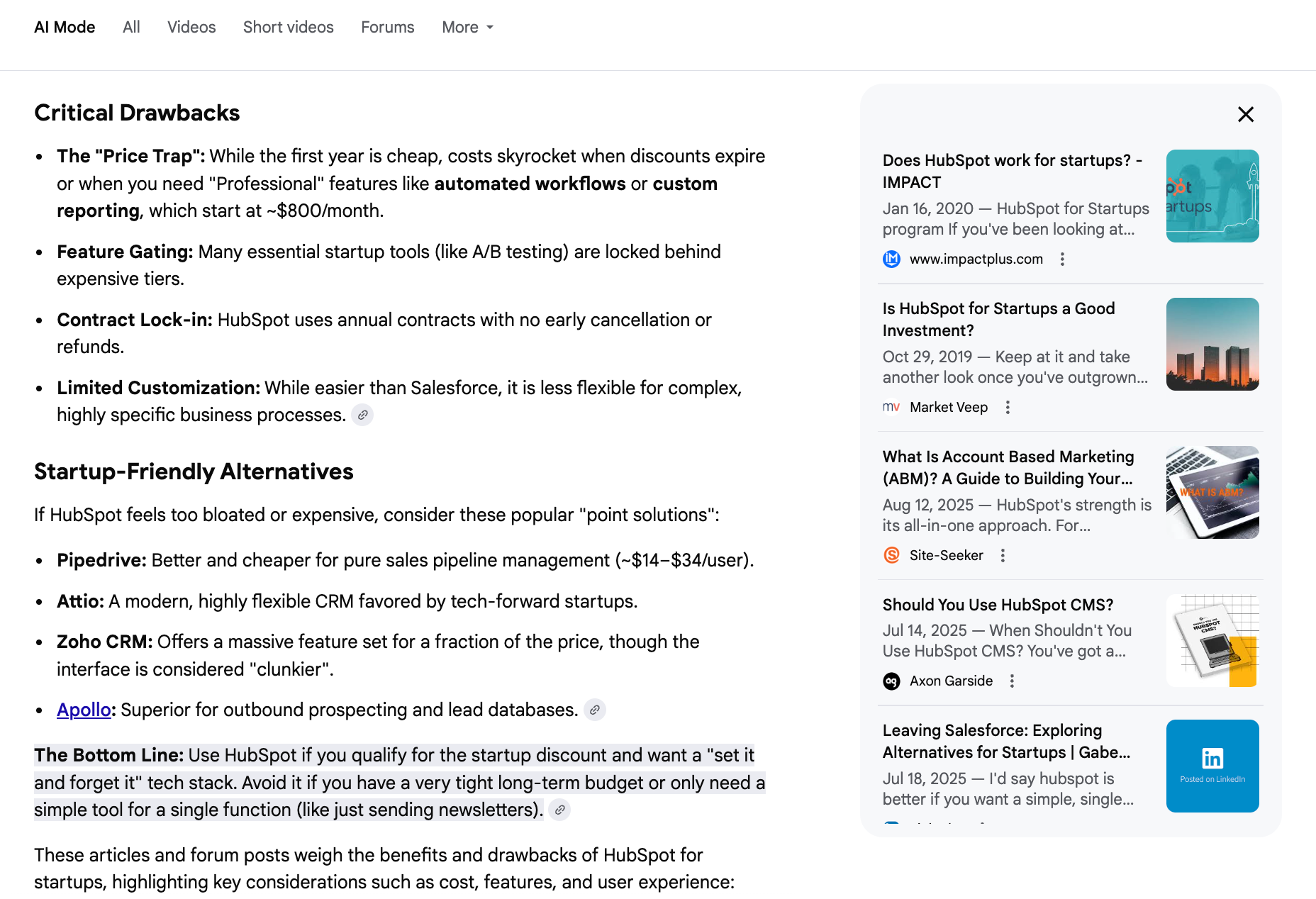
Essentially, if you want to rank for the big question, you have to answer all the sub-questions. This is why topical depth matters more than page-level relevance.
If your content only answers the main question, the AI can use it once. But if your content also answers follow-up questions, you give the model more passages it can reuse across the fan-out.
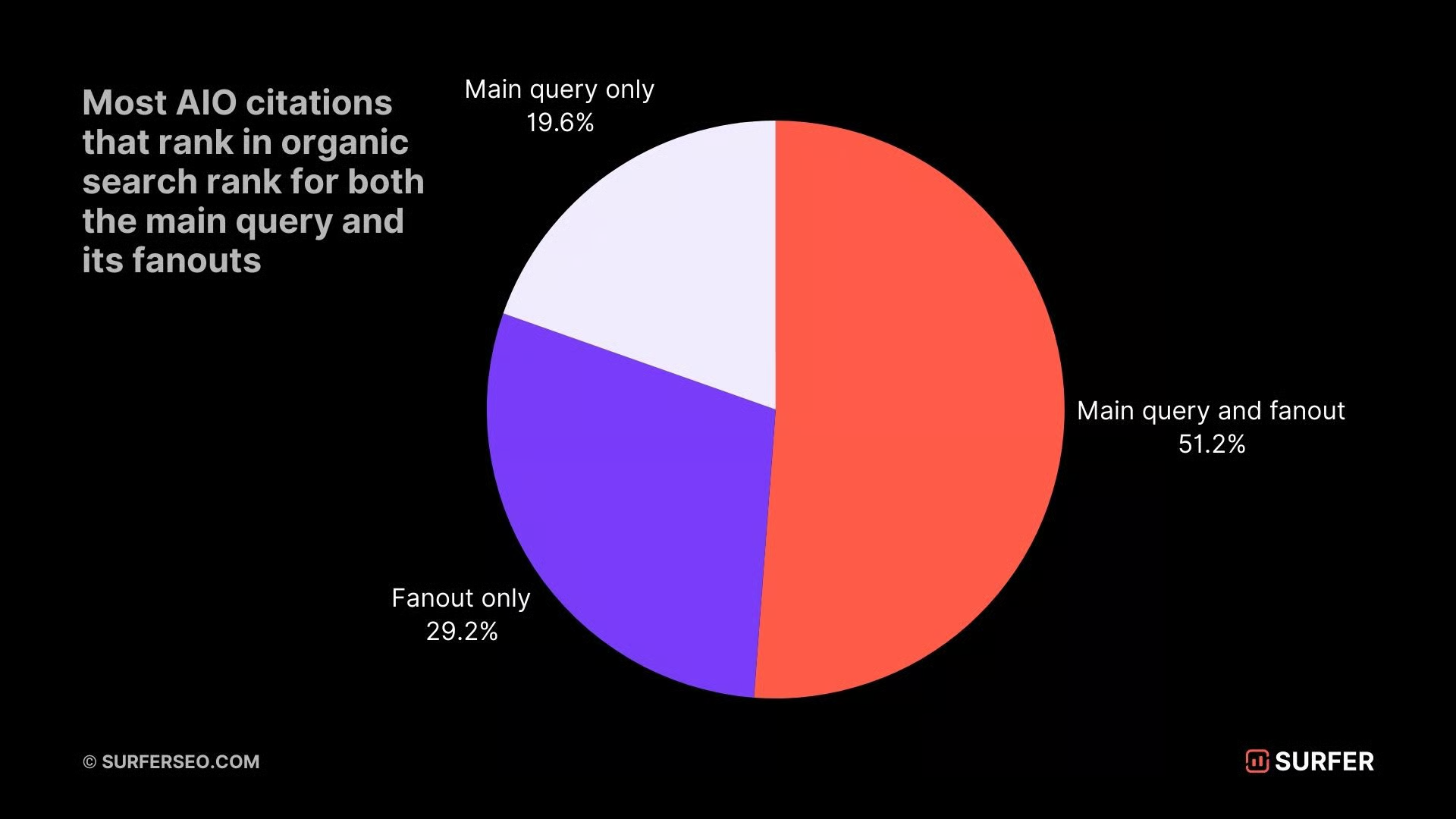
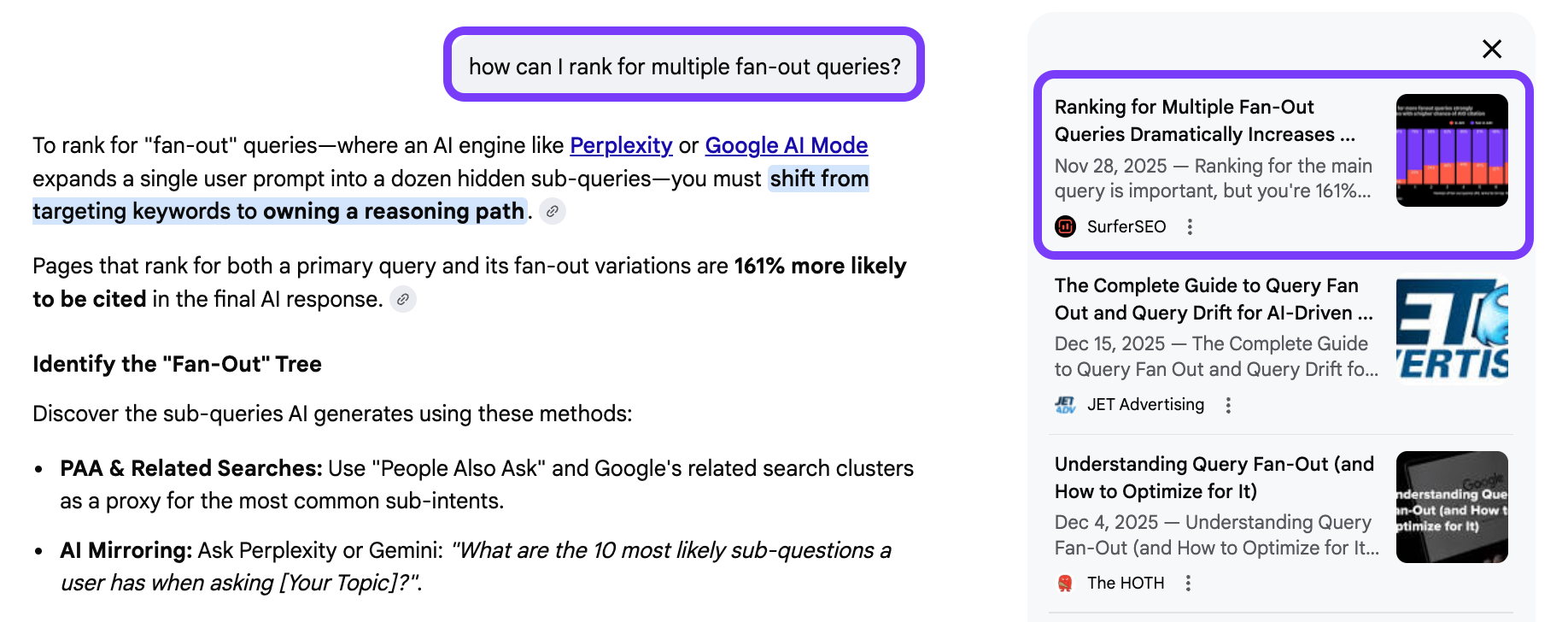
Based on our own analysis for fan-out queries, we found that ranking for sub-queries makes you 49% more likely to be cited than ranking only for the main query.
But ranking for both the main query and its fan-outs makes you 161% more likely to appear in AI answers.
This is where the shift from page relevance to passage relevance happens.
AI systems don’t reuse the full text of pages. They extract specific chunks that answer specific sub-questions. That’s why well-structured pillar pages with clearly defined sections perform better than broad overviews.
HubSpot’s blogs are an example of structuring pages based on specific sub-questions. Each section of their blog becomes a potential citation for a specific query.
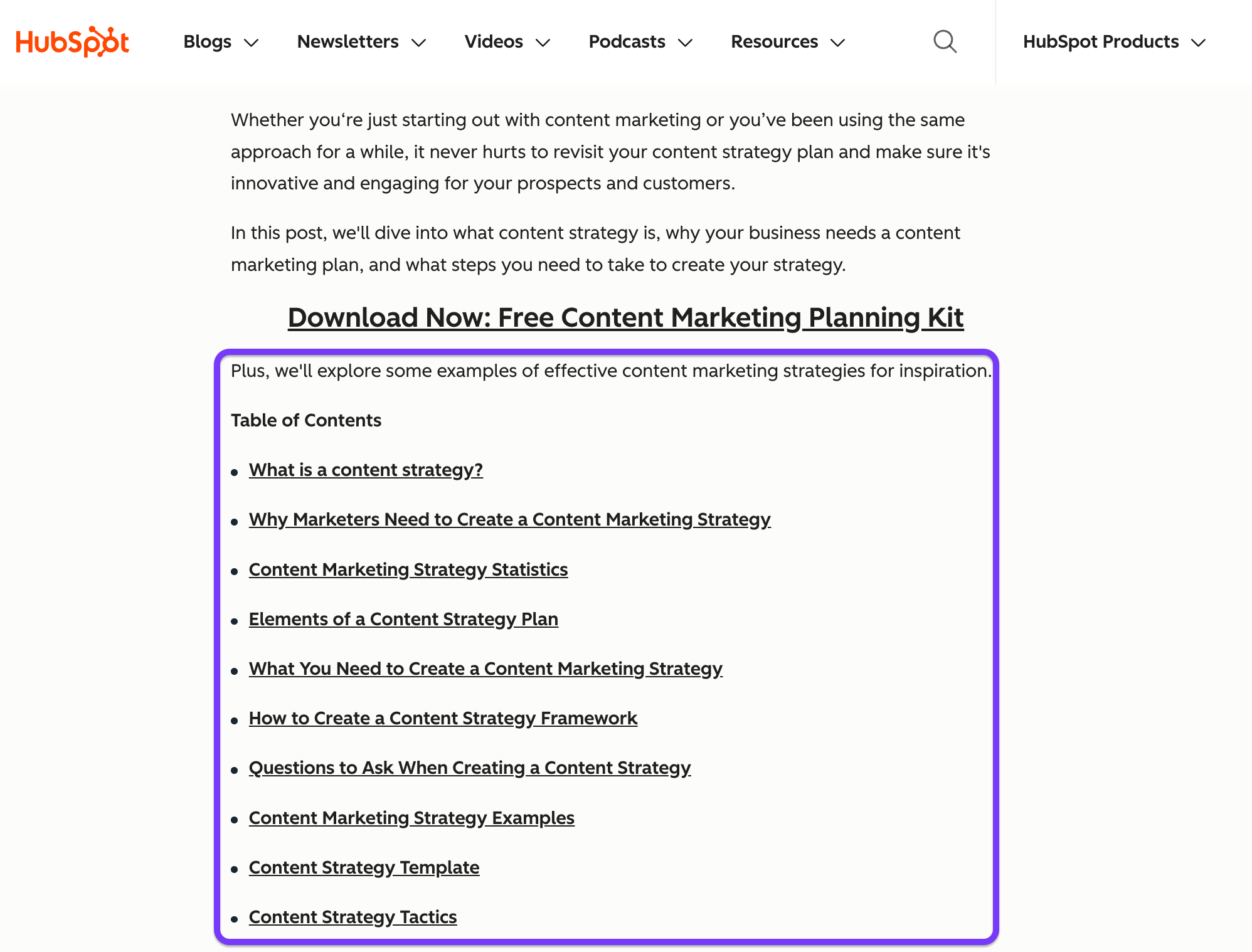
If you haven't noticed, I'm doing the same with this article :)
In practice, this means starting with the fan-out, not the headline keyword. Before writing, map the questions an AI is likely to generate after the main prompt.
Those questions should shape your sections, your internal links, and your supporting pages.
That’s also where clusters come in.
A strong main page anchors the topic, while supporting pages go deeper on individual angles.
For example, if you want your content to be cited for queries about keto diets, you’ll need to create pages around the same topic that cover semantically related questions, including:
- What is a keto diet?
- Does keto help with weight loss?
- Keto diet meal plans
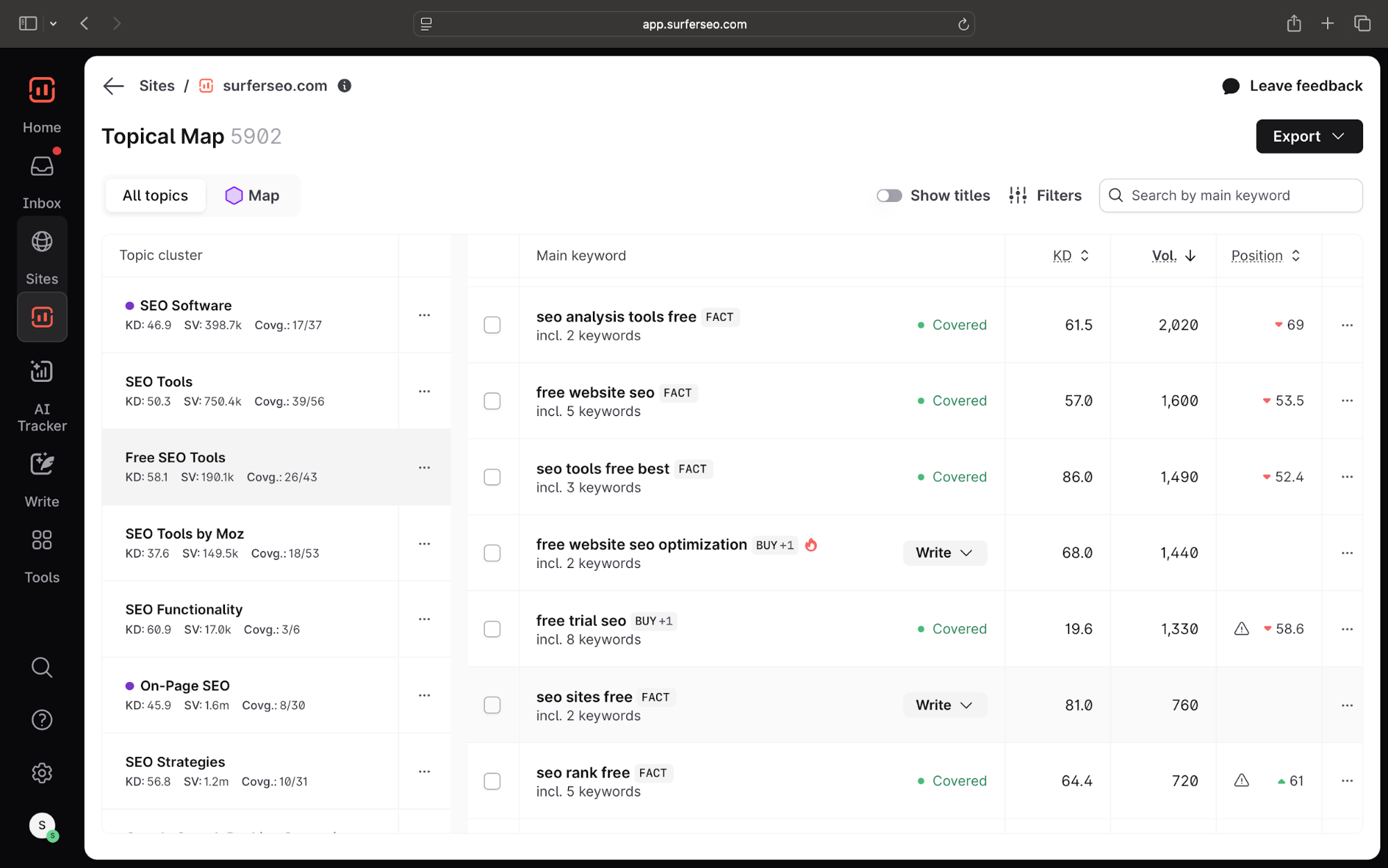
To make this easier, Surfer’s Topical Map finds all semantically-related keywords, clusters them into themes, and identifies low-difficulty subtopics for you.
FAQs are also another way to capture relevant follow-up questions that AI systems commonly generate.
HubSpot’s CRM content is a clear example of this approach. Instead of relying on a single “What is a CRM?” page, they built interconnected content around comparisons, startup use cases, implementation timelines, and data migration.
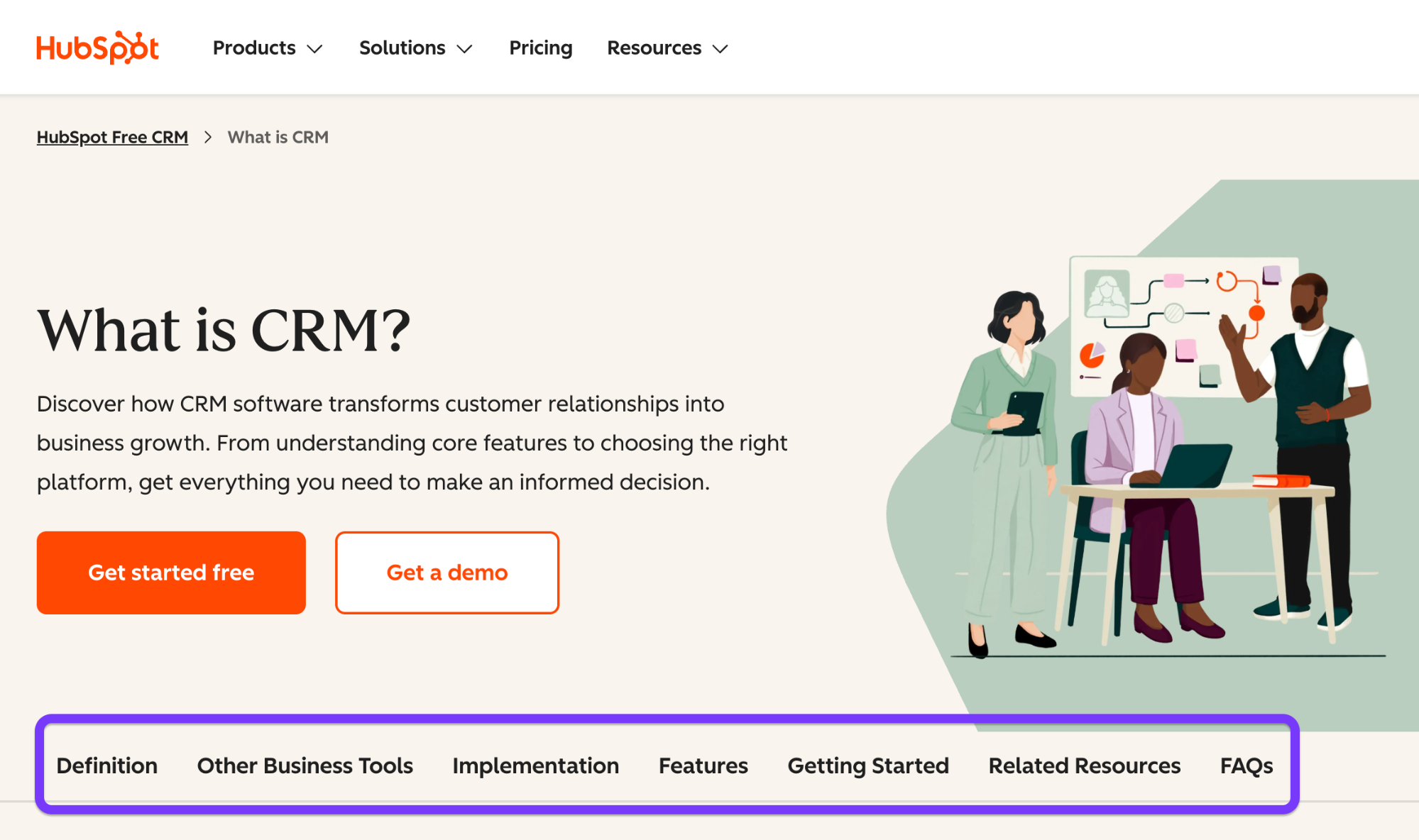
When an AI fans out a query like “Should my startup use a CRM?”, HubSpot content appears across multiple sub-queries—pricing, features, alternatives, and setup—multiplying its chances of being cited.
AI systems aren’t looking for broad summaries. They’re assembling answers from specific pieces. The more relevant pieces you provide, the more often your content shows up in AI-generated text responses.
5. Ship unique information that AI models can safely quote
Artificial intelligence is designed to avoid repeating information it can’t verify. If a claim is wrong, vague, or opinion-based, it’s risky for the model to reuse. If a claim is precise, sourced, and clearly attributed, it’s much safer to quote.
That’s why original data matters so much.
A Princeton GEO study tested 9 optimization methods across 10,000 queries and found that adding statistics or direct quotations increased AI visibility by 30–40%, even when no other optimizations were made.
The content didn’t rank higher because it was longer or paraphrased. It performed better because it was easier for artificial intelligence to trust.
And this pattern shows up clearly in real citation behavior. An Ahrefs analysis found that 67% of ChatGPT’s top 1,000 cited pages come from original research, first-hand data, or academic sources.
Here, you can see that the sources cited by Google AI Mode are all original in-house research—including Surfer.
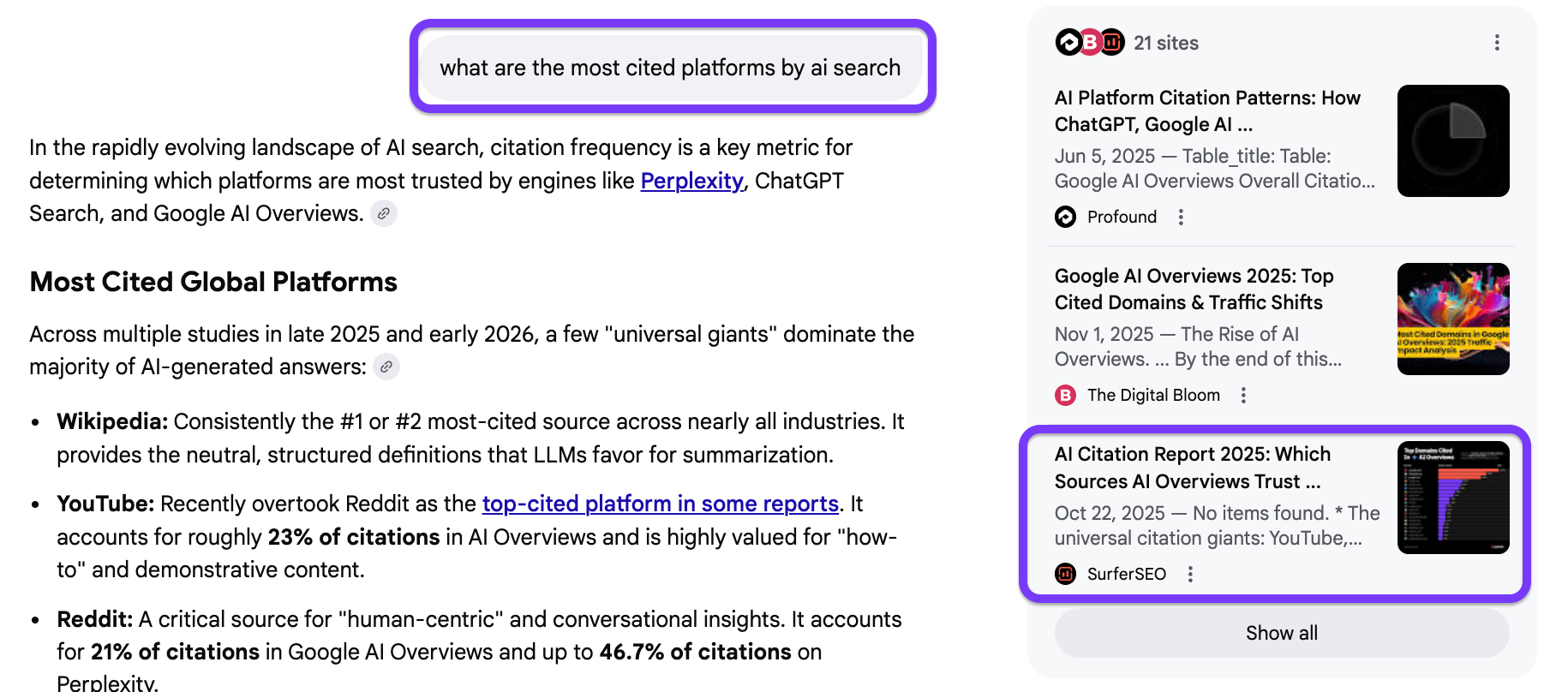
These are the types of sources models rely on when they need to be accurate, not persuasive. And again, you can see that Surfer is cited for another query, where we’ve included first-hand data:
Maximus Labs’ analysis of GEO success stories across different companies also found similar findings.
A monitoring and observability SaaS company published deep technical documentation with concrete metrics, real coding examples, use-case-specific data, and active engagement on Stack Overflow and GitHub discussions. They paired this with detailed comparison pages and honest assessments of alternatives.
Within eight weeks, they saw a 210% increase in AI-sourced traffic and a 12× increase in qualified signups, largely driven by citations in AI answers that reused their documented data points and explanations.
If your content only reframes what already exists, AI has no reason to cite you. But when you introduce something new—a survey result, an internal benchmark, a before-and-after metric—you become a primary source instead of a summary.
Here’s what this looks like in practice for content teams:
- Analyze internal product or usage data and publish aggregated findings.
- Run small, focused surveys and report exact numbers.
- Turn case studies into evidence, not just stories. Establish a baseline, document changes, and outcomes.
- Post benchmarks or white papers related to your industry niche so othes can reference, even if they’re narrow.
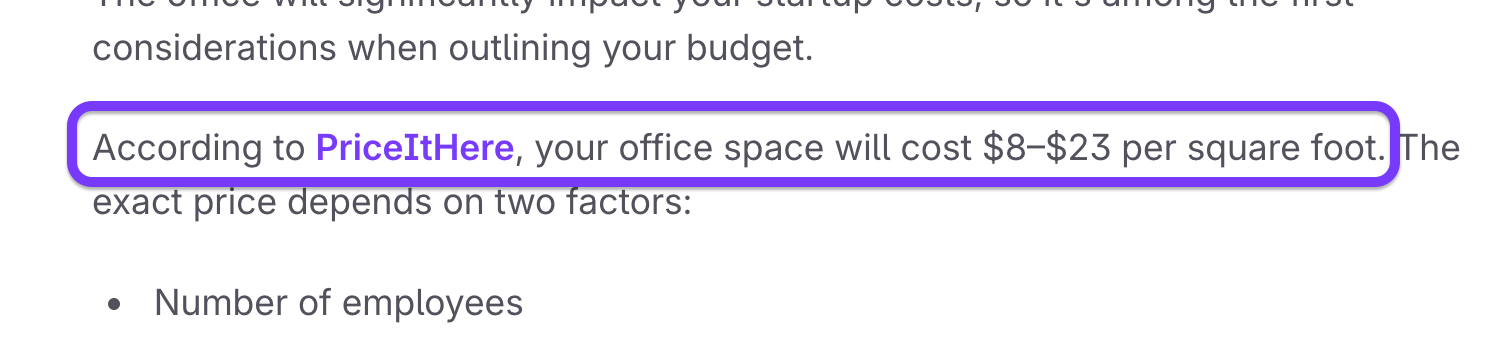
Formatting matters too. AI models strongly favor claims that are easy to lift without distortion. Descriptions like:
According to [Brand]’s 2025 [Study Name], [specific finding].
For YMYL topics (health, finance, legal, or compliance), the bar is even higher. AI systems lean heavily on content backed by academic research, government data, peer-reviewed studies, and clearly credentialed authors.
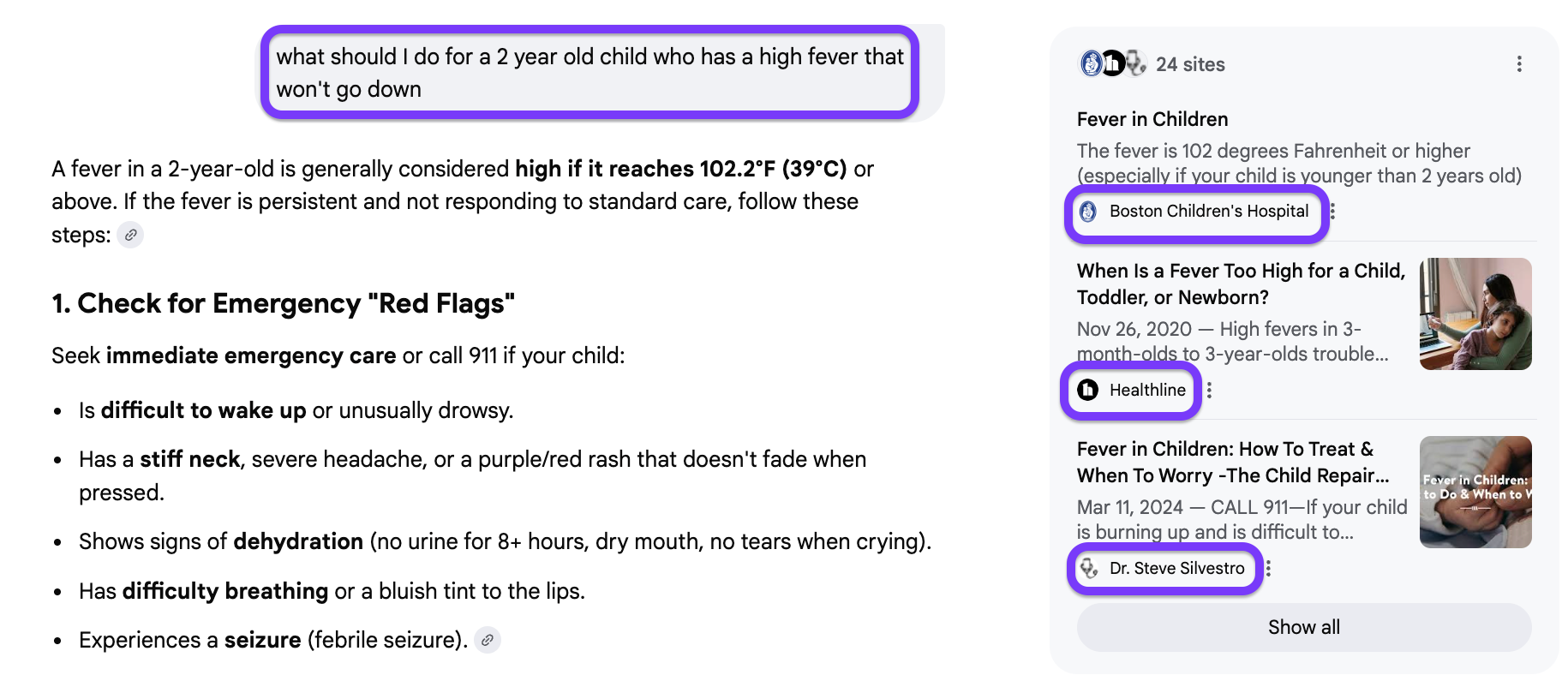
This also helps researchers verify any sources or citations provided by AI tools like ChatGPT before using them in their work.
Ultimately, there's a reinforcing effect at play. Content that consistently cites credible sources signals greater citation discipline. In practice, AI systems tend to cite those pages more often.
If you want to be cited, you need to post something worth quoting. Not opinions or summaries, but information the model can repeat without hesitation.
6. Structure content for AI extraction
AI systems parse, tokenize, and extract discrete chunks of text that can stand on their own inside an answer. If a section can’t be lifted cleanly, it usually isn’t cited.
That means, if your answer to a specific question is buried inside a 10-paragraph story, LLMs are going to have trouble citing it.
In fact, Search Engine Land found that nearly 72.4% of pages cited by ChatGPT contained a short, direct answer immediately after a question-based heading. In practice, answer capsules look something like this:

Answer capsules are self-contained explanations—about 120–150 characters (roughly 20–25 words)—placed directly below a question-based heading.
The same data from Search Engine Land also mentions that if you clutter a 20-word definition with hyperlinks, the AI perceives it as less definitive. So it’s best to hook LLMs first with a clean definition, then elaborate with a link later in the content.
Since AI systems don’t use entire pages, they pull short sections of text that can stand on their own and explain one idea clearly.
These “content chunks” are usually 100–300 tokens (around 75–225 words). That’s why each paragraph or block of content should focus on a single point, so that the AI is “spoon-fed” with the exact snippet it wants to extract in text citation.
In short, pages that perform well in AI answers tend to follow a format that makes extraction easy:
- The heading states the question, so the model knows exactly what problem the section is addressing.
- The first sentence answers that question directly, giving the model a complete response it can reuse as-is.
- The text below adds detail, context, or nuance without changing the core answer.
- Each paragraph focuses on one idea, so the model doesn’t have to separate or reinterpret mixed information.
7. Track and measure AI visibility
One of the biggest challenges around AI visibility is that traditional SEO metrics don’t reflect how LLMs access content.
For example, Google AI Mode frequently uses external content without sending traffic back to it.
Around 75% of Google AI Mode sessions end without an external visit, which means tracking stuff like rankings, traffic, and CTR numbers don’t tell the full story anymore.
That’s why tracking citations and brand mentions inside AI answers matters more than tracking visits alone.
AI tracking tools like Surfer’s AI Tracker are designed to monitor how often your brand appears in ChatGPT answers or AI Overviews, which prompts trigger brand mentions, and how your visibility changes across different AI models over time.
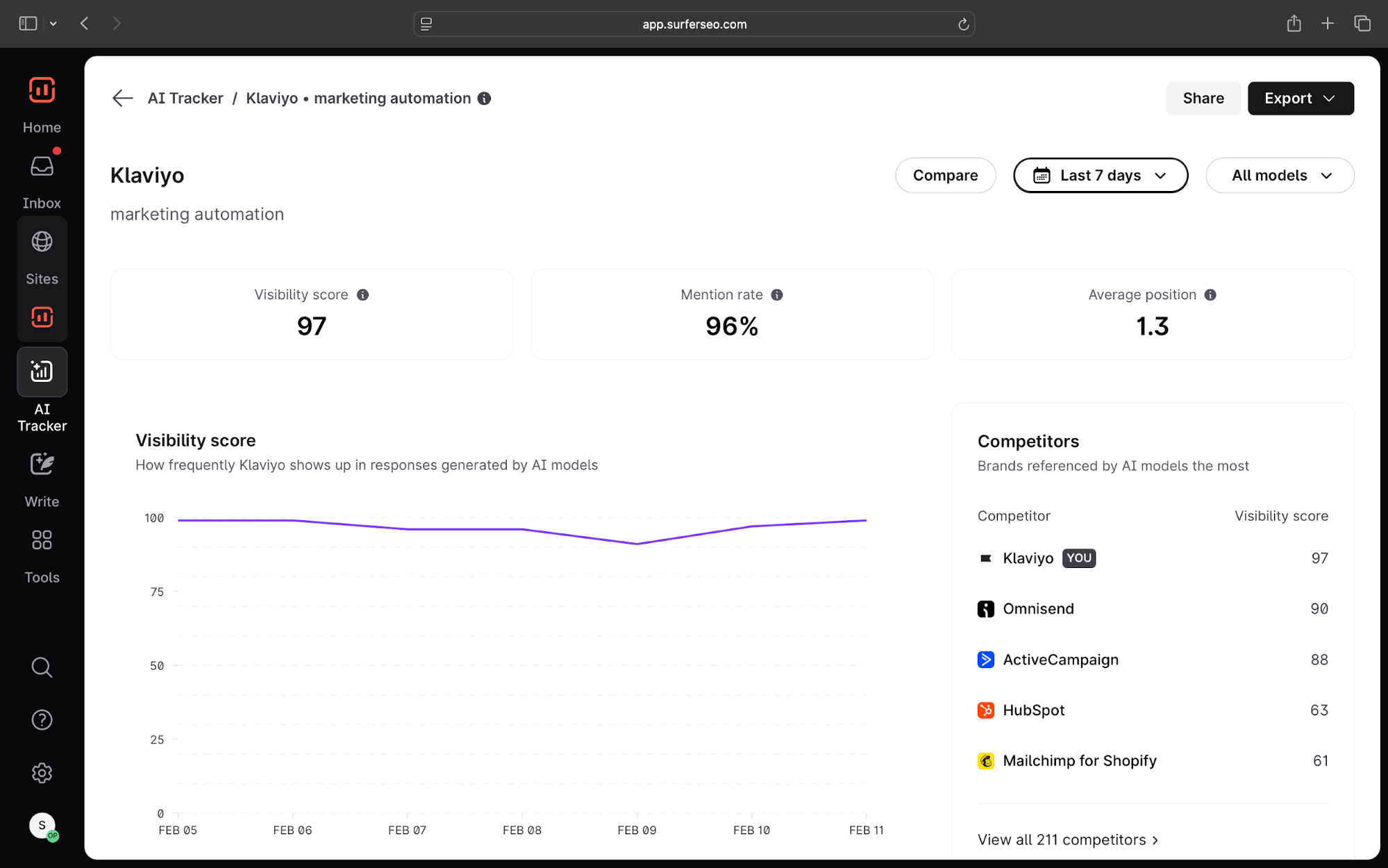
Instead of guessing whether your content is influencing responses or running manual prompts on AI search, you can see the exact AI visibility numbers and where your content is showing up.
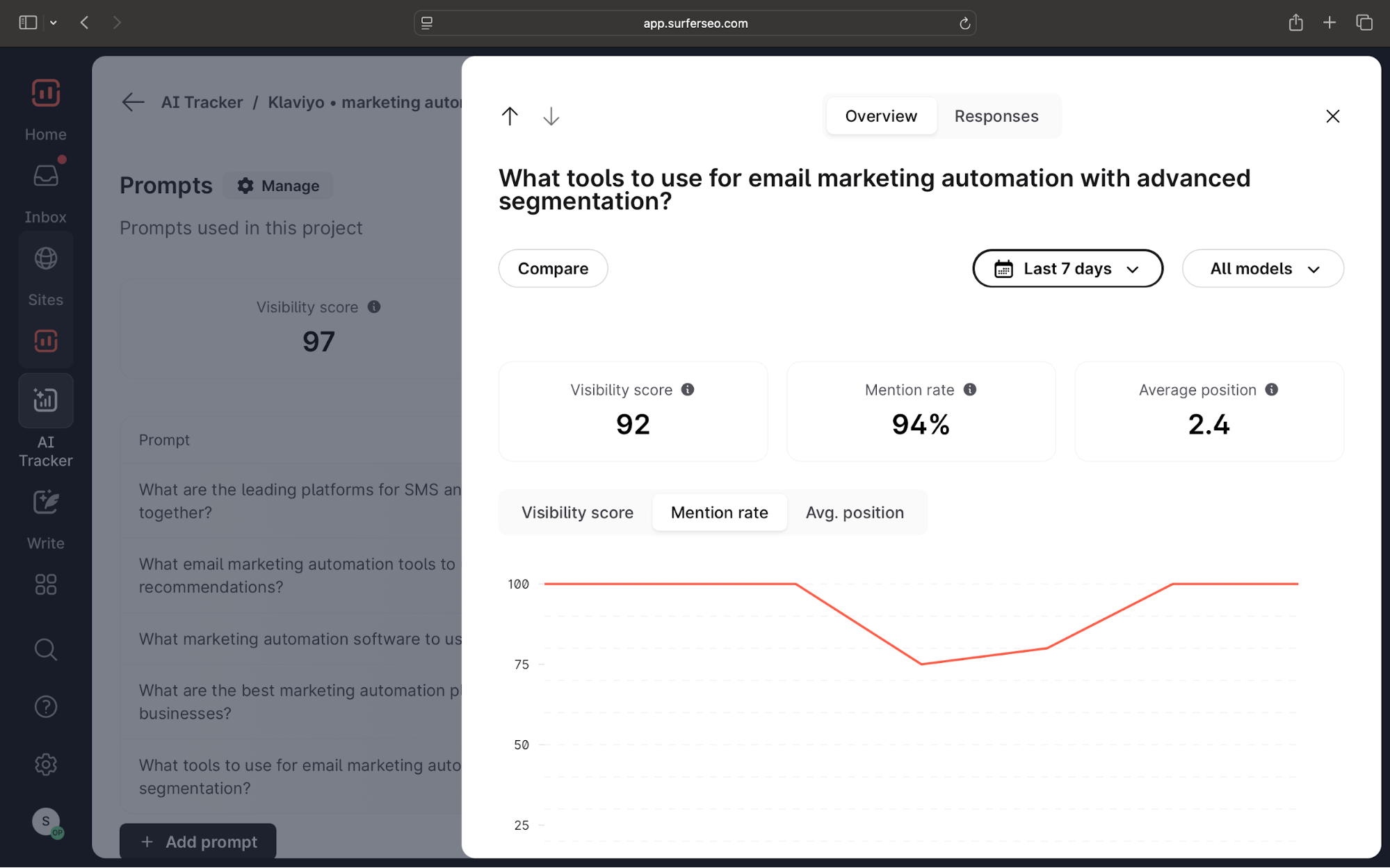
But tracking alone isn’t enough. The real value comes from auditing what already works.
Start by identifying the pages that are already being cited by AI systems and look for patterns:
- Do these pages include short, direct answers?
- Do they reference original data?
- Are these pages clearly structured?
These traits should guide how you optimize the rest of your content, which might not be getting cited by LLM.
And with the Sources report, you can even see the exact AI response that mentions your brand, as well as which pages cover competitors so you have a better idea of what kind of content works for LLM optimization.
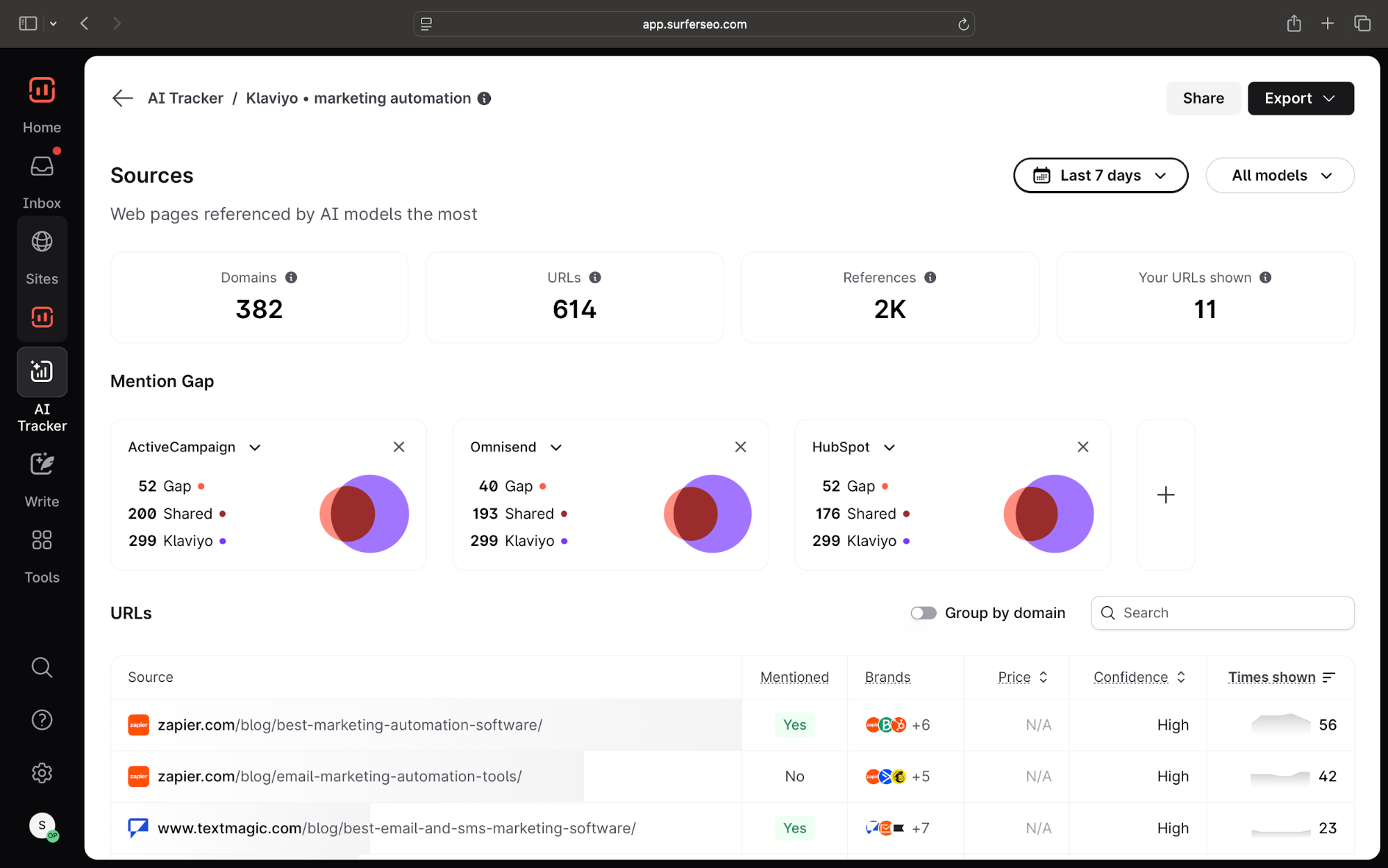
From there, follow these straightforward steps,
- Add answer capsules to high-performing pages that don’t have them yet.
- Inject original data points, statistics, or clearly attributed sources into existing content.
- Update high-impact pages on a monthly or quarterly cadence (especially comparisons, pricing, and top-performing content).
- Boost presence across forums like Reddit, GitHub, review sites, and other social media platforms.
This obviously isn’t a one-time effort. AI visibility improves through iteration and consistency. Slowly prioritize these changes, track how citations shift. Then, refine what works.
Keep in mind that structural updates, like improving page structure, can start influencing AI visibility within days. But building broader authority through original data, topical depth, and consistent updates typically compounds over 3–6 months.
Always remember that the goal isn’t to replace traditional SEO metrics. You’re just layering a new strategy on top.
How to get cited by LLMs and AI tools
LLMs don’t pick sources at random. Once AI algorithms start treating a source as reliable, it tends to reuse that source across related prompts.
One citation increases the likelihood of the next. Over time, that creates a compounding effect.
That’s why getting cited early matters.
Right now, AI systems are still forming their source preferences. They’re deciding which brands, publications, and datasets are safe to rely on.
But that won’t last. As more teams optimize for AI visibility, those source sets will stabilize, and replacing an established source will get much harder.
What content teams need to focus on today is:
- Showing up where AI systems already look, not just on your own site
- Structuring and maintaining content so it’s easy to extract and verify
- Publishing information that’s specific, original, and safe to quote
The priority is no longer just about chasing higher rankings. It’s about being included in the set of sources AI systems already trust when answering questions.




